



2.2.3 Naming and Communication in Distributed Systems
Course subject(s)
2: Functional Requirements
Challenge of Communication in Distributed Systems
The ability to communicate is essential for systems. Even single machines are constructed around the movement of data, from input devices, to memory and persistent storage, to output devices. Although computers are increasingly complex, this communication is well-understood. We include in the typical functional requirements, and modern systems already meet these requirements, that messages arrive correctly at the receiver, that there is an upper limit on the amount of time it takes to read or write a message, and that developers know how much data can be safely exchanged between applications at any point in time. In a distributed system, none of this is true without additional effort.
Similar to applications running on a single machine, a distributed system can only function if its components are able to communicate. But providing communication in a distributed system requires solving additional challenges. For example, the components in a distributed system are asynchronous: they run independently from, and do not wait for, other components. This means components must continue to function, even though communication with other components can start and stop at any time. Another example why communication in distributed systems is more difficult is that the networks used for communication are unreliable. Networks may drop, delay, or reorder messages arbitrarily, and components need to take these possibilities into account. Throughout this section, we explore the science and technology behind successful communication in distributed systems despite these and other challenges.
Protocols for Computer Networking
To enable communication between computers, they need to speak the same protocol. A protocol defines the rules of communication, including (1) which entity can speak, (2) when, and (3) how to represent the data that is communicated.
How a protocol is defined depends on the technology that underlays it. For protocols that directly use the network’s transport layer, they need to define data fields as a sequence of bits or bytes. Defining a protocol on this level, however, has multiple disadvantages. It is labor intensive, the binary messages are challenging to debug, and it is difficult to achieve backward compatibility. Backward compatibility means that newer versions of technology still support older versions. For example, Microsoft’s Xbox One game console supports older games built for their previous console, the Xbox 360. This makes the Xbox One backward compatible with Xbox 360 games. When a protocol defines data fields on the level of bits and bytes, adding or changing what data can be sent while still supporting older implementations is difficult. For these and other reasons, distributed systems often define their protocols on a higher layer of abstraction.
One of the simplest abstractions on top of byte streams is plain-text messages. These are used widely in practice, especially in the older technologies that form the core of the Internet. For example, the Domain Name System (DNS), the Hypertext Transfer Protocol (HTTP), and the Simple Mail Transfer Protocol (SMTP) all use plain-text messages. Instead of defining fields with specified bit or byte lengths, plain-text protocols are typically line-based, meaning every message ends with a new line character (“\n”). The advantages of such protocols are that they are easy to debug by both humans and computers, and that they offer increased flexibility due to variable-length fields. Text-based protocols can easily be changed into binary protocols without losing their advantages, by compressing the data before it is sent over the network.
Moving one more level up brings us to structured-text protocols. Such protocols use specialized languages designed to represent data, and use them to define messages. For example, REST APIs typically use JSON to exchange data. A structured text comes with its own (more complex) rules on how to format messages. Fortunately, many parser libraries exist for popular structured-text formats such as XML and JSON, making it easier for distributed system developers to use these formats without writing the tools themselves
Finally, structs and objects in programming languages can also be used as messages. Typically, these structs are translated to and from structured-text or binary representations with little or no work required from developers. Mapping programming-language-specific data structures to and from message formats are called marshaling and unmarshaling respectively. Marshaling libraries and tools take care of both marshaling and unmarshaling. Examples of marshaling libraries for structured-text protocols include Jackson for Java and the built-in JSON library for Golang. Examples of marshaling libraries for binary formats include Java’s built-in Serializable interface and Google’s Protocol Buffers.
Communication Models for Message Passing
Message passing always occurs between a sender and a receiver. It requires messages to traverse a possibly unreliable communication environment and can start and end at synchronized or arbitrary moments. This leads to multiple ways in which message-passing communication can occur, and thus multiple useful models.
Depending on whether the message in transit through the communication environment is stored (persisted) until it can be delivered or not, we distinguish between transient and persistent communication:
- Transient communication only maintains the message while the sender and the receiver are online, and only if no transmission error occurs. This model is the easiest to implement and matches well with the typical Internet-router based on store-and-forward or cut-through technology. An example here is that real-time games may occasionally drop updates and use local correction mechanisms. This allows in many cases the use of relatively simple designs, but for some game genres can lead to the perception of lag or choppy movement of the avatars and objects.
- Persistent communication requires the communication environment to store the message until it is received. This is convenient for the programmer, but much more complex to guarantee by the distributed system. Worse, this leads typically to lower scalability than approaches based on transient communication due to the higher latency of the message broker storing incoming messages on a persistent storage device as well as potential limits of the number of messages that can be persisted at the same time. An example of the use of a persistent communication system appears in the email system. Emails are sent and received using SMTP and IMAP respectively. SMTP copies email from a client or server to another server, and IMAP copies email from a server to a client. The client can copy the email from their server repeatedly because the email is persisted on the server.
Depending on whether the sender and/or the receiver has to wait (is blocked) in the process of transmitting or receiving, we distinguish between asynchronous communication and synchronous communication:
- In asynchronous communication, asynchronous senders and receivers attempt to transmit and receive, respectively, but will continue to other activities immediately after the attempt, regardless of its outcome. UDP-like communication uses the (transient) asynchronous model.
- In synchronous communication, synchronous senders and receivers block until their operation (request) is confirmed (synchronized). We identify three useful synchronization points: (1) when the request is submitted, that is, when the request has been acknowledged by the communication environment; (2) when the request is dispatched (message/operation delivery), that is, when the communication environment acknowledges the request has been delivered for execution to the other side of the communication; (3) when the request is fully processed (operation completed), that is, when the request has reached its destination and has been fully processed, but before the result of the processing has been sent back (as another message, possibly with the same communication model). In practice, the Message Passing Interface (MPI) standard provides the programmer with the flexibility of choosing between all these approaches to synchronization.
Remote Procedure Calls
Due to the unavailability of shared memory in distributed systems, communication is a means to achieve a common goal among multiple computers. Often, we communicate because one machine, the caller, wants to ask (call on) another machine, the callee, to have them perform some work. This pattern is very typical for how people have used telecommunication systems since their inception, just that here we are dealing with machine-to-machine communication. Remote procedure calls (RPCs) are an abstraction of this communication-enabled process in DCS. Internally, RPC is typically built on top of message passing, and thus can occur according to any of the models introduced in the previous block. RPC or derivatives are still much used today. For instance, Google’s gRPC is a common building block of large parts of the Google datacenter stack. Many uses of REST also closely mimic RPC semantics, much to the disdain of purists who emphasize that REST is supposed to be resource-centric and not procedure-centric. Modern object-oriented variants of RPC such as RMI are often used in the Java community for building distributed applications.
Implementation
Functionally, RPC wants to maintain the illusion that a program would call a local implementation of the service. Since now caller and callee reside on different machines, they need to agree on a definition of what the procedure is: its name and parameters. This information is often encoded in an interface written in an Interface Definition Language (IDL).
In order for local programs to be able to call the service, a stub is created that implements the interface but, instead of doing function execution locally, encodes the name and the argument values in a message that is forwarded to the callee. Since this is a mechanical, deterministic process, the stub can be compiled automatically by a stub generator.
On the server side, the message is received and the arguments need to be unmarshalled from the message so that the function can be invoked on behalf of the client. This is again performed by an automatically generated stub, on this side of the system also often referred to as a skeleton (server stub in the image below)
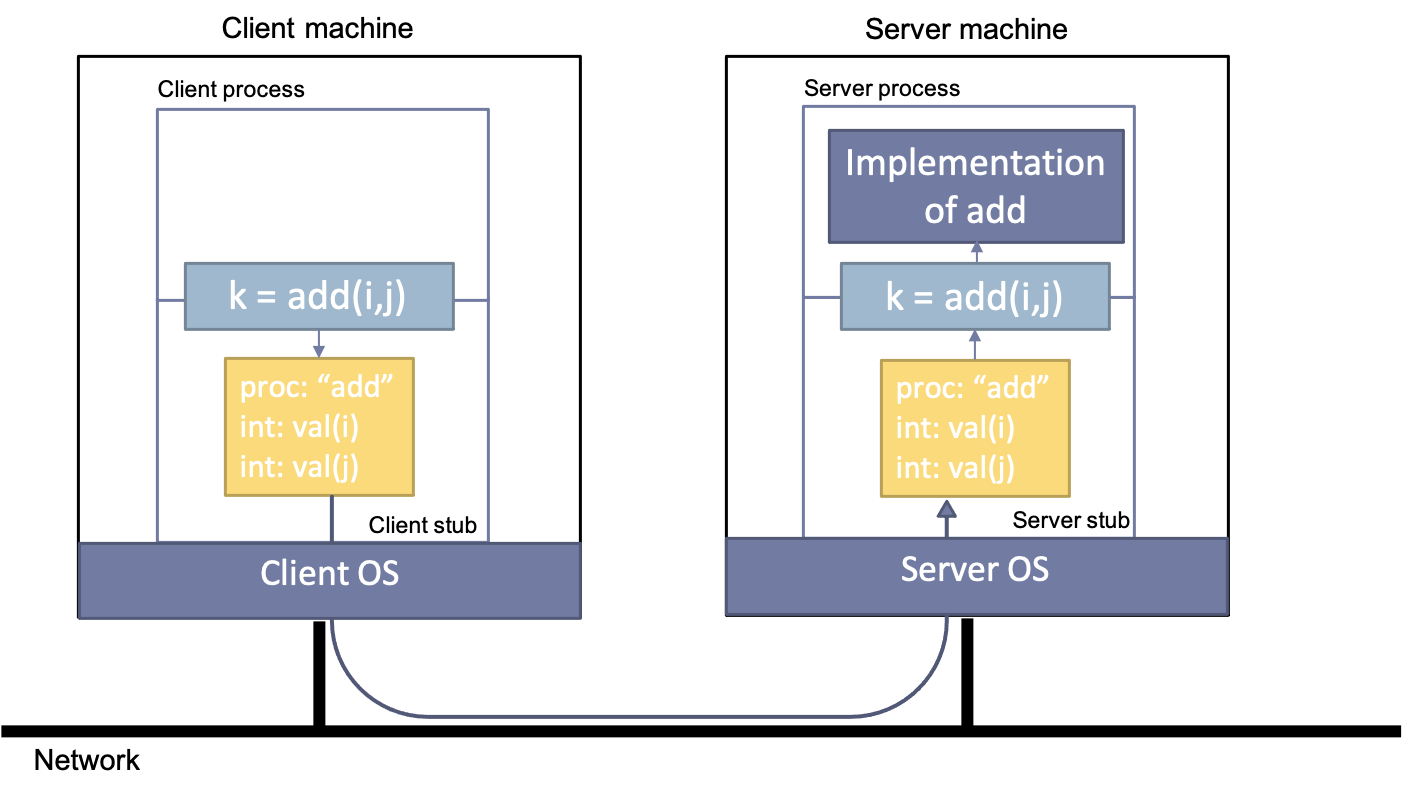
The dynamics of this operation are as follows. When the client calls the procedure on the local stub, the client stub marshals both the procedure name and the provided arguments into a message. This message is then sent to a server that contains the requested procedure. Upon receipt, the receiving stub unmarshals the message and calls the corresponding procedure with the provided arguments. The returned value is then sent back to the client, using the same approach. RPC uses transient synchronous communication to create an interface that is as close as possible to regular procedure calls
From Remote Procedures to Remote Objects
Since the late-1950s, the programming language community has proposed and developed programming models that consider objects, rather than merely operations and procedures for program control. Object-oriented programming languages, such as Java (and Kotlin), Python, and C++, remain among the most popular programming languages. It is thus meaningful to ask the question: Can RPC be extended to (remote) objects?
An object-oriented equivalent of RPC is remote method invocation (RMI). RMI is similar to RPC, but has to deal with the additional complexity of remote-object state. In RMI, the object is located on the server, together with its methods (equivalent of procedures for RPC). The client calls a function on a proxy, which fulfills the same role as the client-stub in RPC. On the server side, the RMI message is received by a skeleton, which executes the method call on the correct object.
Communication Patterns
The messages that are sent between machines, be they sent as plain messages, or as the underlying technology of RPC, show distinct patterns over time depending on the properties of the system that uses them. Below we describe some of the most prevalent communication patterns.
- Request-Reply Request reply is a one-to-one communication pattern where a sender starts by asking something from the receiver. The receiver then takes an action and replies to the sender.
- Publish-Subscribe In publish-subscribe, or pub-sub, one or multiple machines generate periodic updates. If another machine is interested in these updates, they can subscribe to them at the sender. The sender then sends the updates to all the machines that are subscribed. This can work well in games, where players may indicate that they want to receive some updates, but not others.
- Pipeline communication works with producers, consumers, and prosumers. In this messaging pattern, a producer wants to send messages to a particular type of receiver but does not care about which machine this is specifically. This pattern allows long chains and easy load-balancing, by adding more machines to the system with a particular role.
- Broadcast A broadcast is a message sent out by a source and addressed, or received, by all other entities on the network. Broadcast messages are useful for bootstrapping or communicating the global state. An example of bootstrapping is the broadcast DHCP message sent out by a client requesting an IP. An example of broadcasting the global state can be found in games, where a server may inform all players when a new player has joined.
- Flooding is a pattern where a broadcast is repeated by its receivers. This works well for fast information dissemination on non-star-topology networks but also uses large amounts of network resources. Systems that use flooding must also actively stop the flooding once all machines have received the message. One way of doing this is to allow machines to propagate the broadcast only once.
- Multicast In between one-to-one communication such as request-reply, and one-to-all communication such as broadcast is multicast. Here a sender wants to send messages to a particular set of receivers. In a game, the receivers could be teammates, whom the player sends data about themselves that they do not want to share with the opposite team.
- Gossip For some systems the large number of resources required for flooding is out of the question. To still do data dissemination, gossip provides an alternative. In a gossiping exchange pattern, machines periodically contact one random neighbor. They send messages to each other, and then go back to sleep. This pattern allows information to propagate through the entire network with high likelihood, without the intensive resource utilization that flooding requires.
Communication in Practice
Here are some examples of popular messaging systems:
- MPI is a commonly used standard for flexible message-passing. Because it has gained traction in the HPC community, high-performance MPI implementations exist; for example,
MVAPICHdeveloped by the US-based Ohio State University andOpenMPIare considered high-quality implementations. - RabbitMQ is a message broker, a middleware system that facilitates sending and receiving messages. It is similar to Kafka, but not specifically built for stream-processing systems.
- Protocol Buffers are a cross-platform, cross-language method of (de)marshaling data. This is useful for HTTP or other services that do not come with their own data marshaling libraries.
- Netty is a framework for building networked event-driven systems. It supports both custom and existing protocols such as HTTP and Protocol Buffers.
- Akka HTTP is part of the Akka distributed-systems framework. It provides both a client- and server-side framework for building HTTP-based services.
- gRPC is an RPC library that marshals messages using Protocol Buffers.
- CORBA is another popular and long-running RPC library.
Challenges of Naming in Distributed Systems
(Material related to naming developed by Jesse Donkervliet, for the Distributed Systems course at Vrije Universiteit of Amsterdam).
Distributed systems can consist of hundreds or even thousands of entities at any given point. An entity can be a machine, a service, or a serverless function. Depending on the workload, an entity may be active for any duration between multiple years to only a few seconds. Whatever their lifetime, these entities must be able to communicate with each other. This is where naming comes in. Naming provides the entities in the distributed system to identify each other and set up communication channels.
In the remainder of this section dedicated to naming in distributed systems, we show how naming challenges can be addressed with naming schema, which are techniques used to assign names to entities, and naming services, which use the naming schema and other elements to offer name-related services to the distributed system.
Naming Schema in Distributed Systems
Naming schemes (schema) are the rules by which names are given to individual entities. There are an infinite number of ways in which to ascribe names to entities. In this section, we identify and discuss three categories of naming schema: simple naming, hierarchical naming, and attribute-based naming. We discuss them in turn.
Simple Naming: Focusing on uniquely identifying one entity among many is the simplest way to name entities in a distributed system. Such a name contains no information about the entity’s location or role.
Advantages: The main advantage of this approach is simplicity. The effort required to assign a name is low—the only requirement is that the name is not already taken. Various approaches can simplify even this verification step, at the cost of a (very low) probability the name may cause a collision with another chosen name.
Disadvantages: A simple name shifts the complexity of locating it to the naming service.
Addressing the downside of simple naming, distributed systems can use rich names. Such names not only uniquely identify an entity, but also contain additional information, for example, about the entity’s location. This additional information can simplify the task of the naming service. As examples of rich names, we discuss hierarchical naming and attribute-based naming.
Hierarchical Naming: In hierarchical naming, names are allowed to contain other names, creating a tree structure.
Namespaces are commonly used in practice. Examples include file systems, the DNS, and package imports in Java and other languages. These names consist of a concatenation of words separated by a special character such as “.” or “/”. The tree structure forms a name hierarchy, which combines well with, but is not the same as, a hierarchical name resolution approach. When a hierarchical naming scheme is combined with hierarchical name resolution, a machine is typically responsible for all names in one part of the hierarchy. For example, when using DNS to look up the name https://masters.vu.nl, we first contact one of the DNS root servers. These forward us to the “nl” servers, which forward us to the “vu” servers, which in turn know where to find “masters.vu.nl”.
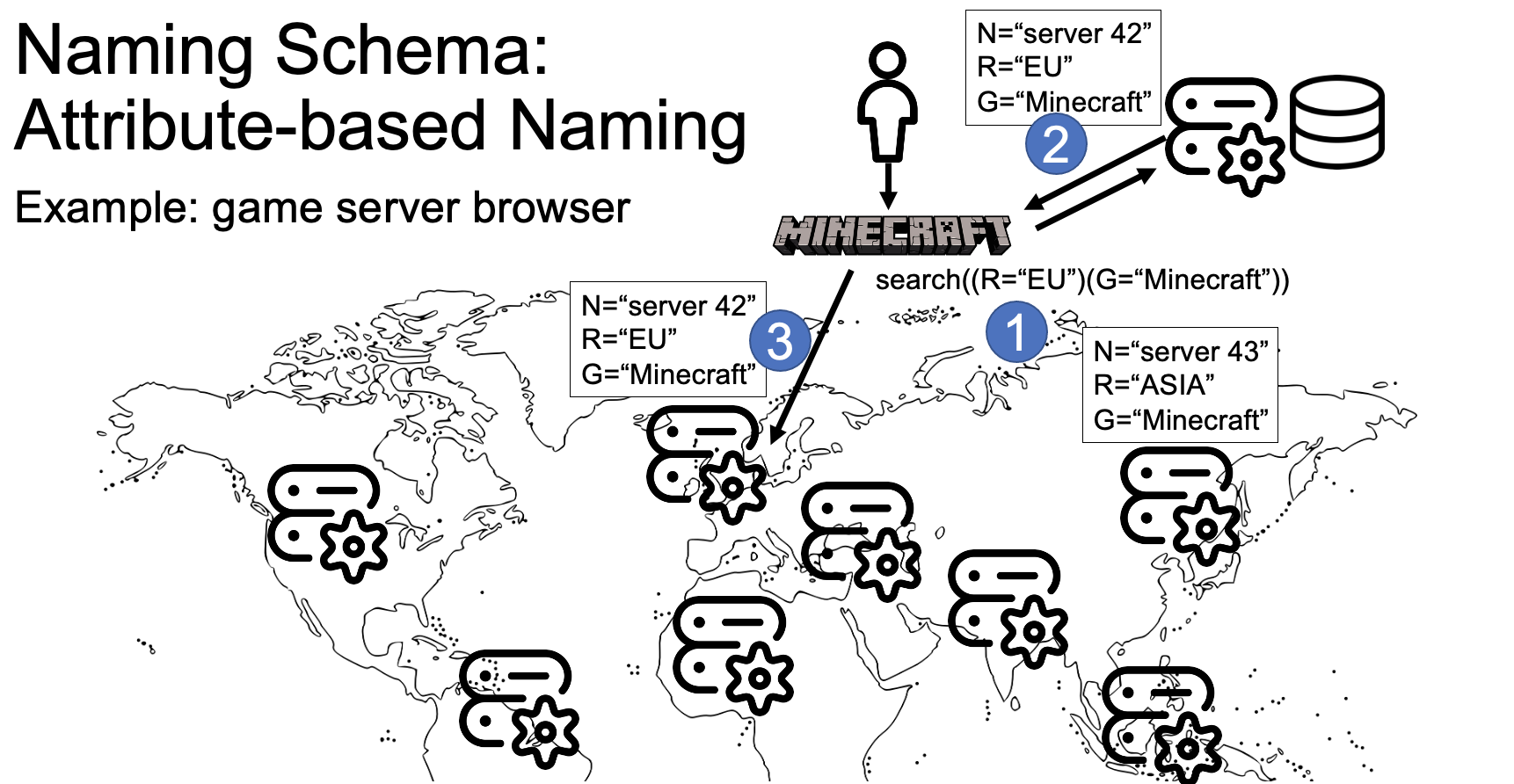
Figure 1. Simplified attribute-based naming for a Minecraft-like game. Steps 1-3 are discussed in the text.
Attribute-Based Naming names entities by concatenating the entity’s distinguishing attributes. For example, a Minecraft server located in an EU datacenter may be named “R=EU/G=Minecraft”, where “R” indicates the region and “G” indicates the game.
Figure 1 illustrates how a player in the example might find a game of Minecraft located in an EU datacenter. In step 1, the game client on the player’s computer automates this, by querying the naming service to “search((R=“EU”)(G=“Minecraft”))“. Because the entries in attribute-based naming are key-value pairs, searches are easy to make, and also partial searches can result in matches. In step 2, the naming service returns the information that “server 42” is a server matching the requested properties. In step 3, the game client resolves the name and connects to the specific machine that runs the Minecraft server in the EU.
Naming schema in practice: The lightweight directory access protocol (LDAP) is a name-resolution protocol that uses both hierarchical and attribute-based naming. Names consist of attributes, and can be found by performing search operations. The protocol returns all names with matching attributes. In addition to the attributes, names also have a distinguished name, which is a unique hierarchical name similar to a file path. This name can change when, for example, the name is moved to a different server. (We will see this feature in action when we discuss distributed ecosystems for science, where many copies of the same file can exist, so accessing one specific replica needs LDAP support.) Because LDAP is a protocol, multiple implementations exist. ApacheDS is one of these implementations.
Naming Services in Distributed Systems
Once every entity in the system has a name, we would like to use those names to address our messages. Networking approaches assume that we know, for each entity, on which machine it is currently running. In distributed systems, we want to break free of this limitation. Modern datacenter architectures often run systems inside virtual machines that can be moved from one physical machine to the next in seconds. Even if instances of entities are not moved, they may fail or be shut down, while new instances of the same service are started on other machines. Naming services address such complexity in distributed systems.
Name resolution: A subsystem is responsible for maintaining a mapping between entity names and transport-layer addresses. Depending on the scalability requirements of the system, this could be implemented on a single machine, as a distributed database, etc. (We will encounter much more complex subsystems for name resolutions in the distributed ecosystems for science section.)
Publish-Subscribe systems: Naming services can be more complex than allowing entities to look up the address of other entities. For example, a publish-subscribe service takes over this responsibility from the entities in the distributed system. Instead, the entities only have to indicate which messages they are interested in receiving. In other words, they subscribe to certain messages with the naming service. This subscription can be based on multiple properties. Common properties for publish-subscribe systems include messages of a certain topic, with certain content, or of a certain type. When an entity wants to send a message, it sends it not to the interested entities, but to the naming service. The naming service then proceeds by publishing the message to all subscribed entities.
The publish-subscribe service is reminiscent of the bus found in single-machine systems. For this reason, the publish-subscribe service is often called the “enterprise bus”. A bus provides a single channel of communication to which all components are connected. When one component sends a message, all others are able to read it. It is then up to the recipients to decide if that message is of interest to them. Publish-subscribe differs from this approach by centralizing the logic that decides which messages are of interest to which entities.
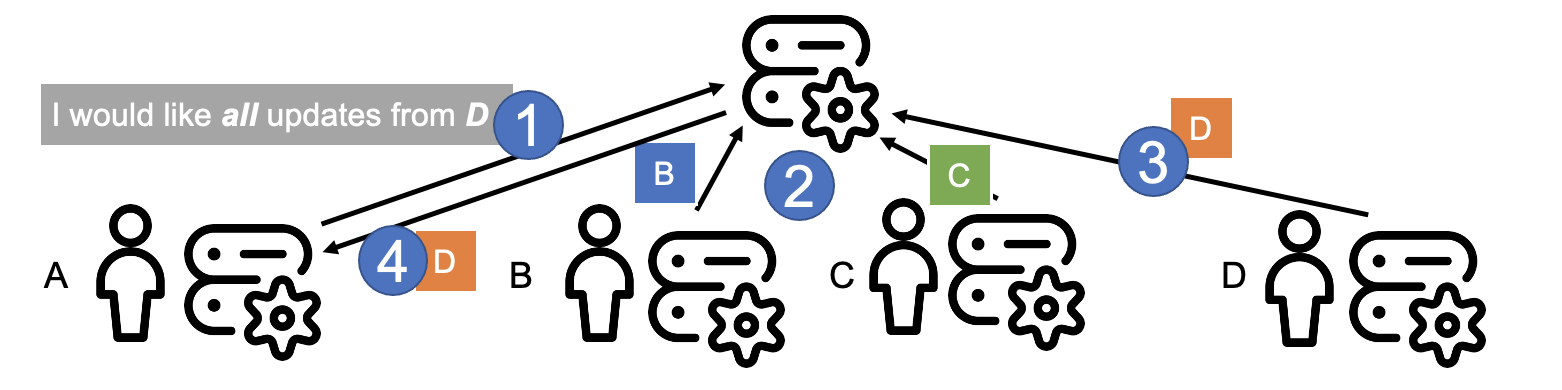
Figure 2. Publish-subscribe example.
Figure 2 illustrates the operation of publish-subscribe systems, in practice. In step 1, user A announces their intention to receive all updates from user D; this forms the subscription for all messages from user D. This request could be much more complex, filtering only some messages. Also, the same user can make multiple subscriptions. The system will ensure the request is enforced; for a discussion about the modern technology stack to achieve this in practice, see our description of a serverless approach in [1].
In step 2, users B and C send updates (messages) to the publish-subscribe system. These are stored (published) and may be forwarded to users other than A.
In step 3, user D sends a new message to the publish-subscribe system. The system analyzes this message and decides it fits the subscription made by user A. Consequently, in step 4, user A will receive the new message.
In practice: The publish-subscribe approach is widely deployed in production systems. Apache Kafka is a publish-subscribe platform for message streams. It is suitable for systems that produce and reliably process large quantities of messages. Kafka is part of a larger ecosystem. It can be used with other systems such as Hadoop, Spark, Storm, Flink, and others.
References:
[1] Simon Eismann, Joel Scheuner, Erwin Van Eyk, Maximilian Schwinger, Johannes Grohmann, Nikolas Herbst, Cristina L. Abad, Alexandru Iosup (2021) Serverless Applications: Why, When, and How? IEEE Softw. 38(1).

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/