



2.2.6 Consistency in Distributed Systems
Course subject(s)
2: Functional Requirements
We discussed in the previous section how replication, a simple operational technique, can help improve distributed systems’ performance, scalability, and availability. But simply replicating data or compute tasks does not yield these benefits. Because different replicas can modify the same data or state, inconsistency may arise.
We discuss in this section how consistency can be achieved.
The Data Store
The essence of any discussion about consistency is the abstract notion of the data store. Data stores can differ when servicing diverse applications, types of operations, and kinds of transactions, but essentially a data store:
- Stores data across multiple machines (replicas),
- Receives a stream of various operations, of which most common are Read (query data) and Write (update data); it is common for data stores to support only a few operations, sometimes only Reads and Writes,
- Enforces that the operations execute correctly, that is, delivering consistent results, and
- In practice, also supports other, functional and non-functional, requirements.
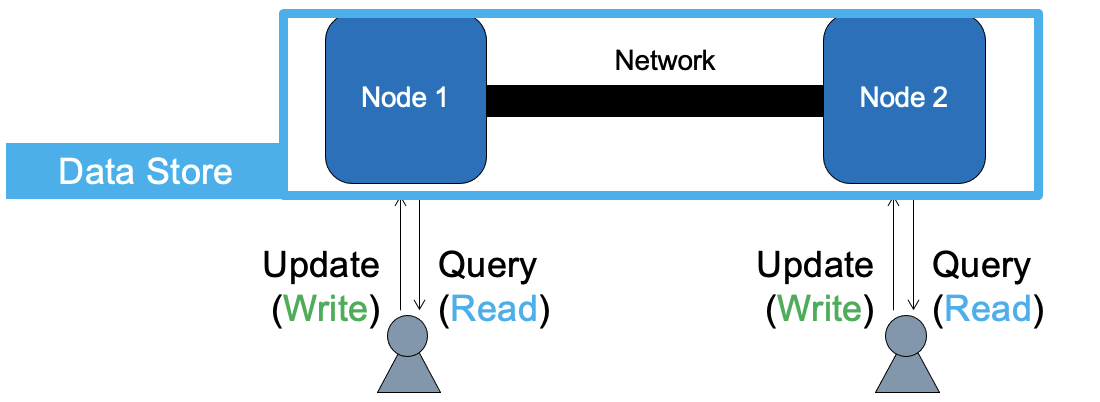
Figure 1. Data store with a single primary user.
Many applications only have a single primary user. You are likely the only one accessing your email, for business or leisure. You may have a private Dropbox folder, which you may want to access at home, on the train, wherever you stay long enough to want to store new photos, etc. Many mobile-first users recognize these and similar applications. Figure 1 depicts the data store for the single primary user. Here, the user can connect from one location (or device), write new information – a new email, a new Dropbox file, then disconnect. After moving to a new location (or device), and reconnecting, the user should be able to resume the email and access the latest version of the file.
Other applications have multiple users, writing together information to the same shared document, changing together the state of an online game, making together transactions affecting many shared accounts in a large data management system, etc. Here, the data store again has to manage the data-updates, and deliver correct results when users query (read).
What is Consistency?
The main goal of consistency is:
| Goal: achieving consistency, which means establishing and enforcing a mutual agreement between the data store and its client or clients, on the expected effect of system operations on data. |
In a distributed system, achieving consistency falls upon the consistency model and consistency (enforcing) mechanisms. Consistency models determine which data and operations are visible to a user or process, and which kind of read and write operations are supported on them. Consistency mechanisms update data between replicas to meet the guarantees specified by the model. We explore in the remainder of this section mainly consistency models.
Who works in consistency? Consistency has been the focus of many great computer scientists. Daniel Abadi [1] and Peter Bailis [2] stand out from the new generation.
Classes of consistency models: The consistency model offers guarantees, but outside the guarantees, almost anything is allowed, even if it seems counter-intuitive.
We identify two main classes of consistency models:
- Strong consistency: an operation, particularly a query, can return only a consistent state.
- Weak consistency: an operation, particularly a query, can return inconsistent state, but there is an expectation there will be a moment when consistent state is returned to client. Sometimes, the model guarantees which moment, or which (partial) state.
How does the consistency model fundamentally affect the operation of the distributed system using it?
A distributed system lacking any consistency model can easily behave in ways that are counter-intuitive and downright detrimental. In the introduction to this module, I presented a situation when editing in Overleaf led to (unwanted) garbling of my text. I lost quite some time fixing the text until I gave up and rewrote that part. But in my case, the text was clearly garbled, and I could mark the entire text and remove its errors by simply deleting it all; I just pressed the Backspace key on my keyboard. In other situations, especially with multiple users or non-trivial data, the corruption of the data store into an inconsistent state can be much more difficult to detect. Even when the inconsistency is detected, fixing it could be much more difficult. So, in practice, inconsistency is not a good idea.
Looking at the classes of consistency models we have just introduced, it would be tempting to always aim for strong consistency. After all, inconsistency can have negative consequences, and clients seem to dislike it. This is the view ACID databases take, spurred by the strict requirements of applications in banking, control of critical operations, etc.
The strictest forms of consistency are so costly to maintain that, in practice, there may be some tolerance for a bit of inconsistency after all. The CAP theorem already suggests availability may suffer under these strict models, and, later in the chapter, the PACELCA framework further suggests also performance is a trade-off with how strict the consistency model can be. (Tellingly, seminal reports from, among others, Bailis, indicate most common databases are not actually supporting ACID in their default settings.)
References:
[1] Read, for example, http://dbmsmusings.blogspot.com
[2] Read, for example, http://www.bailis.org/blog/
Focus on Weak Consistency Models
Many views on consistency models exist. Traditional results from theoretical computer science and formal methods indicate (i) what single-operation, single-object guarantees and (ii) what multi-operation, multi-object guarantees of consistency (named differently) can be given for data stores. Notions of (i) linearizability or (ii) serializability emerged to indicate Write operations can seem instantaneous yet a real-time or an arbitrary total order can be enforced, respectively.
Building from these results, (1) in operation-centric consistency models, a single client can access a single data object, (2) in transaction-centric consistency models, multiple clients can access any of the multiple data objects, and (3) in application-centric consistency models, specific applications can tolerate some inconsistency or have special ways to avoid some of the costly update operations. We cover here the former and the latter category.
Operation-Centric Consistency Models (single client, single data object, data store with multiple replicas):
Several important models emerged in the past four decades, and more may continue to emerge:
Sequential consistency: All replicas see the same order of operations as all other replicas. This is desirable, but of course prohibitively expensive.
What other operation-centric consistency models can designers use?
Causal consistency weakens the promises, but also the needs to operate, of sequential consistency: As for sequential consistency, causally related operations must still be observed in the same order by all replicas. However, for other operations that are not causally related, different replicas may see a different order of operations and thus of outcomes. Important cases of causal consistency, with important applications, include:
- Monotonic Reads: Subsequent reads by the same process always return a value that is at least as recent as a previous read. Important applications include Calendar, inventories in online games, etc.
- Monotonic Writes: Subsequent writes by the same process follow each other in that order. Important applications include email, coding on multiple machines, your bank account, bank accounts in online games, etc.
- Read Your Writes: A client that writes a value, upon reading it will see a version that is at least as recent as the version they wrote. Updating a webpage should always, in our expectation, make the page refresh show the update.
- Writes Follow Reads: A client that first reads and then writes a value, will write to the same, or a more recent, version of the value it read. Imagine you want to post a reply on social media. You expect this reply to appear following the post you read.
Causal consistency is still remarkably difficult to ensure in practice. What could designers use that is so lightweight it can scale to millions of clients or more? The key difficulty in scaling causal consistency is that updates that multiple replicas to coordinate could hit the system concurrently, effectively slowing it down to non-interactive responses and breaking scalability needs. A consistency model that can delay when replicas need to coordinate would be very useful to achieve scale.
Eventual consistency: Absent new writes, all replicas will eventually have the same contents. Here, the coordination required to achieve consistency can be delayed until the system is less busy, which may mean indefinitely in a very crowded system; in practice, many systems are not heavily overloaded much of the time, and eventual consistency can achieve good consistency results in a matter of minutes or hours.
Application-Centric Consistency Models: We only sketch the principle of operation of these consistency models.
Under special circumstances, there is no need for the heavy, scalability-breaking coordination needed to ensure consistency we saw for operation-centric consistency models (and can have an intuition about the even heavier transaction-centric consistency models). Identifying such circumstances in general has proven very challenging, but good patterns have emerged for specific (classes of) applications.
Applications where small inconsistencies can be tolerated include social media, where for example information can often be a bit stale (but not too much!) without much impact, online gaming, where slight inconsistencies between the positions of in-game objects can be tolerated (but large inconsistencies cannot), and even banking where inconsistent payments are tolerated as long as their sum does not exceed the maximum amount allowed for the day. Consistency models where limited inconsistency is allowed, but also tracked and not allowed to go beyond known bounds, include conits (we discuss them in the next section).
Conflict-free Replicated Data Types (CRDTs) focus on efficiently reconciling inconsistency situations. To this end, they are restricted to data types that only allow monotonic operations, and whose replicas can always be correctly reconciled by taking the union of operations across all replicas. For example, suppose the data-object represents a set, to which items can only be added. In this case, it does not matter in which order the objects are added, or which replica executes the operation of addition. In the end, the correct set is obtained by executing every addition operation in the system across all replicas. In this example, removal or modification of an object would not be allowed because they are not monotonic.
We conclude by observing the designer of distributed systems and applications must have at least a basic grasp of consistency, and of known classes of consistency models with a proven record for exactly that kind of system or application. This can be a challenging learning process, and mistakes are costly.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/