



3.2.1 Importance of Performance
Course subject(s)
3: Non-Functional Requirements
Why is performance important?
Firstly, computer systems were developed originally with the goal of performing tasks faster than the state of the art approaches—manual computers, mechanical calculators, then analog computers for science and engineering.
Secondly, modern computer science goals focus much more on efficiency, a consequence of the business world becoming a large investor in computing. Performance is a common element in the way efficiency is assessed and thus remains important in this context.
Finally, industry relies on performance to provide QoS or quality of experience (QoE). Long-term, the computer industry was built on an expectation of continuous performance improvements, e.g., Moore’s Law (1960s-2006), and any slowdown from this expectation affects how the entire industry is perceived by users and investors. For interactive applications, the significant increase in performance since the mid-1950s to today means that the new generation of users expects no performance glitches, e.g., no lag. For key apps and hot functions, there is a general expectation of optimization or at least that systems satisfice performance requirements well. For scientific and engineering apps, the community expects 10x-100x improvements to be possible every few years; for example, the core article describing the Darwin system for genomics discusses a 15,000x performance improvement.
What are the consequences of a lack of performance?
Besides not meeting expectations, a lack of performance for one system can have cascading consequences on others: if one system does not perform well, it can slow down an entire ecosystem. When distributed systems cannot mask even a temporary lack of performance, users notice, which alters their normal behavior and can lead to various unwanted actions. Users may not conclude their transactions with the system, for example, by not clicking through a search query or by not concluding a payment for the current shopping cart. Users may quit, temporarily or forever. Users may even learn how to abuse the system to get the performance they need, for example, by running redundant requests and canceling the copies once one of their requests starts executing, thus blocking the queue for everyone else; another example is of users running workloads on the headnode of the cluster.
Why do systems lack performance?
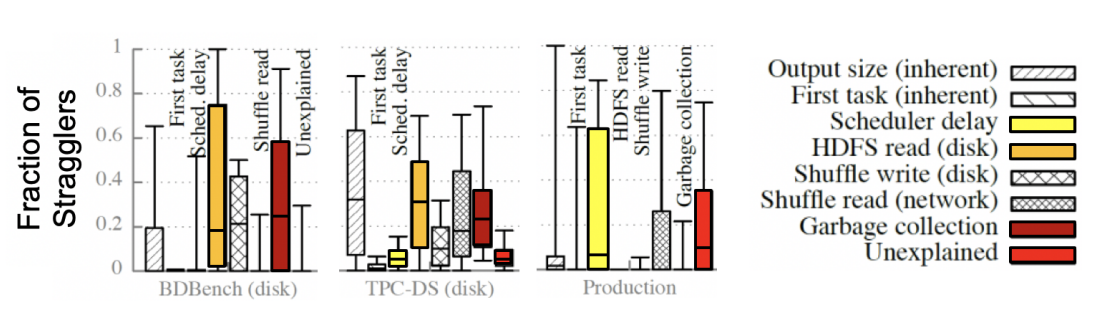
We identify two important reasons systems do not perform as well as we want them to. Firstly, high overhead, which means a system spends resources and time on management, rather than making workload progress. The figure below depicts various sources of overhead for Spark, a popular distributed ecosystem for data analytics. The figure depicts overheads inherent to the workload, such as the size of the output, but also overheads due to the operation of the system, such as the delay due to scheduling Spark tasks, the delay due to reading from the disk, and the delay due to the system performing garbage collection. Overheads may also be unknown, awaiting for scientists and engineers to discover their underlying phenomena. For example, this Figure depicts a category labeled “Unexplained”, which appears particularly in the production workload, and very little in the benchmark workloads of BDBench and TPC-DS. Secondly, performance issues may be due to the system’s lack of scalability, which is exhibited when a system slows down unacceptably when trying to run larger workload, whether with or without more resources.
Can we improve performance without considering other aspects of distributed systems?
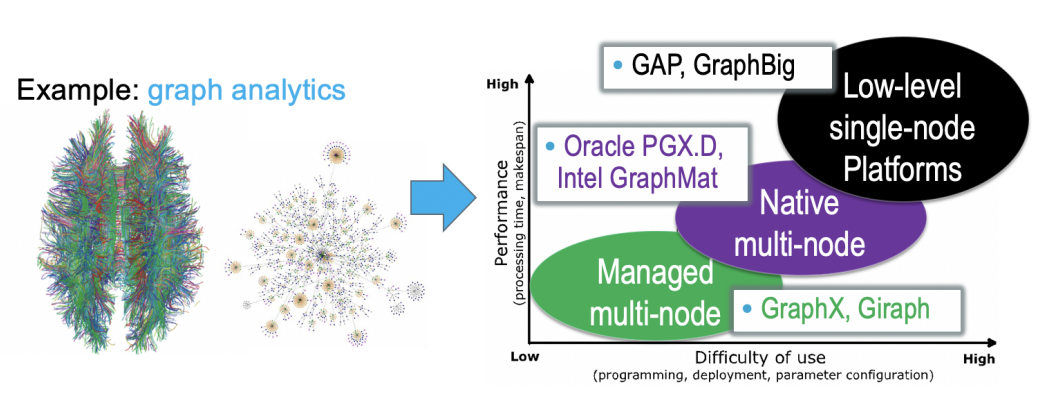
The simple answer is “No”. Making systems perform better means in practice making a trade-off with other functional and non-functional requirements. One common trade-off in systems is that of performance with ease of use. The figure below depicts this trade-off for graph processing. Systems that focus on a single node exploit low-level parallelism and engineer the code to use each available resource can achieve very high performance (per resource), but have high development complexity and require detailed expertise to use. Systems that can run distributed graph analytics and use a specialized programming model are relatively easier to use, but in doing so lose in performance to single-node systems (for the same scale). Last, systems that can run distributed graph analytics and use a general programming model deliver the least performance in this design-space, but are very comfortable to use and learning the programming model allows developers to create applications beyond graph processing.
Can we simply optimize everything?
Although in theory feasible and in concept desirable, in practice optimizing the performance of every part of the distributed (eco)system is a bad strategy. This is because distributed systems are typically complex, even when taken individually; moreover, their performance depends on the input workload and sometimes even on user actions at runtime.
Most importantly, distributed ecosystems are comprised of multiple systems, each responding differently to their share of executing the overall system input. Instead of trying to optimize everything, and instead of treating performance alone, a pragmatic approach is to manage performance, that is, to have a process that treats performance as a continuum and in relation with other non-functional requirements.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/