



2.2.5 Replication in Distributed Systems
Course subject(s)
2: Functional Requirements
To provide a seamless experience to their users, distributed systems often rely on data replication. Replication allows companies such as Amazon, Dropbox, Google, and Netflix to move data close to their users, significantly improving non-functional requirements such as latency and reliability.
We study in this section what replication is and what are the main concerns for the designer when using replication. One of the main such concerns, consistency of data across the replica, relates to an important functional requirement and will be the focus of the next sections in this module.
What is Replication?
The core idea of replication is to repeat essential operations by duplicating, triplicating, and generally multiplying the same service or physical resource, thread or virtual resource, or, at a finer granularity and with a higher level of abstraction, data or code (computation).
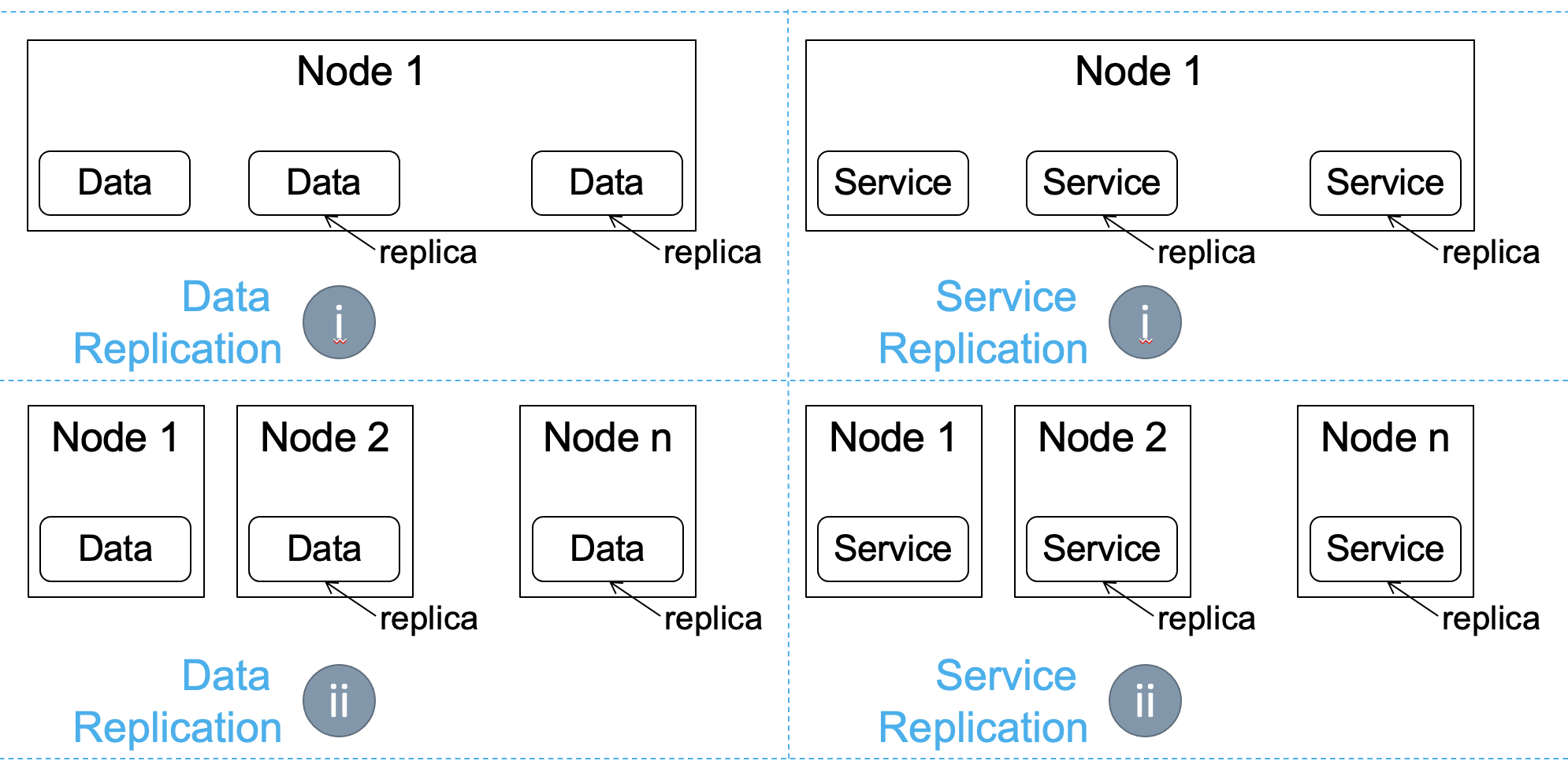
Figure 1. Data and service sharing.
Like resource sharing, replication can occur (i) in time, where multiple replicas (instances) co-exist on the same machine (node), simultaneously, or (ii) in space, where multiple instances exist on multiple machines. Figure 1 illustrates how data or services could be replicated in time or in space. For example, data replication in space (Figure 1, bottom-left quadrant) places copies of the data from Node 1 on several other nodes, here, Node 2 through n. As another example, service replication in time (Figure 1, top-right quadrant) launches copies of the service on the same node, Node 1.
To clarify replication, we must further distinguish it from other operational techniques that use copies of services, physical resources, threads, virtual resources, data, computation, etc. Replication differs from other techniques in many ways, including:
- Unlike partitioning data or computation, replication makes copies of (and then uses) entire sources, so entire datasets, entire compute tasks, etc. (A variant of replication, more selective, focuses on making copies of entire sources, but only if sources are considered important enough.)
- Unlike load balancing, replication makes copies of the entire workload. (Selective replication only makes copies of the part of the workload considered important enough.)
- Unlike data persistence, checkpointing, and backups, replication techniques repeatedly act on the replicas, and access to the source replica is similar to accessing the other replicas.
- Unlike speculative execution, replication techniques typically consider replicas as independent contributors to overall progress with the workload.
- Unlike migration, replication techniques continue to use the source.
General benefits of replication
Replication can increase performance. When more replicas can service users, if each can deliver roughly the performance of the source replica, the service effectively increases its performance linearly with the number of replicas; in such cases, replication also increases the scalability of the system. For example, grid and cloud computing systems replicate their servers, thus allowing the system to scale to many users with similar needs.
When replicating in space, because the many nodes are unlikely to all be affected by the same performance issue when completing a share of the workload, the entire system delivers relatively stable performance; in this case, replication also decreases performance variability.
Geographical replication, where nodes can be placed close-to-users, can lead to important performance gains, guided by the laws of physics, particularly the speed of light.
Replication can lead to higher reliability and to what practice considers high availability: in a system with more replicas, more of them need to fail before the entire system becomes unavailable, relative to a system with only one replica. The danger of a single point of failure (see also the discussion about scheduler architectures, in Module 4) is alleviated.
Consider one of the largest outages in the past year, occurring at Microsoft’s Teams, Xbox Live, and Azure services, an outage so serious it made the news, as reported by the BBC [1]. According to the BBC, “tens of thousands of users” self-reported failures, and Microsoft admitted the failures touched “a subset of users”. However, the Microsoft approach of replicating their services, both in time and in space, allowed most of its hundreds of millions of users to continue working, even while the others were experiencing failures when accessing the replicas servicing them. The many replicas of the same service prevent partial failures from spreading system-wide. In one of our studies [2], we observed many of these situations across the services provided by Microsoft, Amazon, Google, Apple, and others; some of these failures are not considered important enough to be reported by these companies.
General drawbacks of replication:
In high-availability services, replication is a common mechanism to make the system available. Typically, a single replica provides the service, with the others available if the primary replica fails. Such systems cost more to operate. (The extra cost may be worthwhile. For example, many business-critical services run with services where at least two replicas exist; although the cost of operation for the IT infrastructure effectively doubles, the higher likelihood the services will be available when needed prevents much more costly situations when the service is needed but not available. There is also a reputational cost at play, where the absence of service may cause bad publicity well beyond the cost of the service.)
When multiple replicas can perform the same service concurrently, their local state may become different, a consequence of the different operations performed by each replica. In this situation, if the application cannot tolerate the inconsistency, the distributed system must enforce a consistency protocol to resolve the inconsistency, either immediately, at some point in time but with specific guarantees, or eventually. As explained during the introduction, the CAP theorem indicates consistency is one of the properties of distributed systems that cannot be easily achieved, and in particular it presents trade-offs with availability (and performance, as we will learn at the end of this module). So, this approach may offset and even negate some of the benefits discussed earlier in this section.
References:
[1] The BBC, Microsoft says services have recovered after widespread outage, Jan 2022.
[2] Sacheendra Talluri, Leon Overweel, Laurens Versluis, Animesh Trivedi, Alexandru Iosup (2021) Empirical Characterization of User Reports about Cloud Failures. ACSOS 2021.
Replication Approaches
In a small-scale distributed system, replication is typically achieved by executing the incoming stream of tasks (requests in web and database applications, jobs in Module 4) either (i) passively, where the execution happens on a single replica, which then broadcasts to the others the results, or (ii) actively, where each replica receives the input stream of tasks and executes it. However, many more considerations appear as soon as the distributed system becomes larger than a few nodes serving a few clients.
Many replication approaches have been developed and tested in practice in larger, even global-scale, distributed systems. Depending on the scale and purpose of the system, we consider here the principles of three aspects of the replication problem: (i) replica-server location, (ii) replica placement, and (iii) replica updates. Many more aspects exist, and in general replication is a rich problem that includes many of the issues present in resource management and scheduling problems in distributed systems (see Module 4): Who? What? When? For how long? etc.
Replica-server location: Like any data or compute task, replicas require physical or virtual machines on which to run. Thus, the problem of placing these machines, such that their locations provide the best possible service to the system and a good trade-off with other considerations, is important. This problem is particularly important for distributed systems with a highly decentralized administration, for which decisions taken by the largely autonomous nodes can even interfere with each other, and for distributed systems with highly volatile clients and particularly those with high churn, where the presence of clients in one place or another can be difficult to predict.
Replica-server location defines the conditions of a facility location problem, for example, finding the best K locations out of the N possible, subject to many performance, cost, and other constraints, with many theoretical solutions from Operations Research.
An interesting problem is how should new replica locations emerge. When replica-servers are permanent, for example, as game operators run their shared sites, or web operators mirror the websites, all that is needed is to add a statically configured machine. However, to prevent resource waste, it would be better to allow replica-servers to be added or removed as needed, related to (anticipated) load. (This is the essential case of many modern IT operations, which underlies the need for cloud and serverless computing.) In such a situation, derived from traditional systems considerations, who should trigger adding or removing a replica-server, the distributed system or the client? A traditional answer is both, which means that the designer must (1) consider whether to allow the replica-server system to be elastic, adding and removing replicas as needed, and (2) enable both system- and client-initiated elasticity.
Replica placement: Various techniques can help with placing replicas on available replica-servers.
A simplistic approach is to place one replica on each available replica-server. The main advantage of this approach is that each location, presumably enabled because of its good capability to service clients, can actually do so. The main disadvantages are that this approach does not enable replication in time, so multiple replicas located in the same location when enough resources exist, and rapid changes in demand or system conditions cannot be accommodated. (Longer-term changes can be accommodated by good management of replica-server locations.)
Another approach is to use a multi-objective solver to place replicas in the replica-server topology. The topological space can be divided, e.g., into Voronoi diagrams; conditions such as poor connectivity between adjacent divisions can be taken into account, etc. Online algorithms often use simplifications, such as partitioning the topology only along the main axes, and greedy approaches, such as placing servers first in the most densely populated areas.
Replica updates:
What to update? Replicas need to achieve a consistent state, but how they do so can differ by system and, in dynamic systems, even by replica itself (e.g., as in [3] for an online gaming application). Two main classes of approaches exist: (i) updating from the result computed by one replica (the coordinating-replica), and (ii) updating from the stream of input operations that, applied identically, will lead to the same outcome and thus a consistent state across all replicas. (Note (i) corresponds to the passive replication described at the start of this section, whereas (ii) corresponds to active replication.)
Passive replication typically consumes fewer compute resources per replica receiving the result. Conversely, active replication typically consumes fewer networking resources to send the update to all replicas. In section 2.2.7, Consistency for Online Gaming, Virtual Environments, and the Metaverse, we see how these trade-offs are important to manage for online games.
When to perform updates? With synchronous updates, all replicas perform the same update, which has the advantage that the system will be in a consistent state at the end of each update, but also the drawbacks of waiting for the slowest part of the system to complete the operation and of having to update each replica even if this is not immediately necessary.
With asynchronous updates, the source informs the other replicas of the changes, and often just that a new operation has been performed or that enough time has elapsed since the last update. Then, replicas mark their local data as (possibly) outdated. Each replica can decide if and when to perform the update, lazily.
Whom? Who initiates the replica update is important.
With push-based protocols, the system propagates modifications to replicas, informing the clients when replica-updates must occur. This means replicas in the system must be stateful, thus able to consider the need to propagate modifications by inspecting the previous state. This approach is useful for applications with high ratios of operations that do not change the state, relative to those that change it (e.g., high read:write ratios). With this approach, the system is more expensive to operate, and typically less scalable, than when it does not have to maintain state.
With pull-based protocols, clients ask for updates. Different approaches exist: clients could poll the system to check for updates, but if the frequency is polling is too high the system can get overloaded, and if it is too low (i) the client may get stale information from its state, or (ii) the client may have to wait for a relatively long time before obtaining the updated information from the system, leading to low performance.
As is common in distributed systems, a hybrid approach could work better. Leases, where push-based protocols are used while the lease is active, and pull-based protocols are used outside the scope of the lease, are such a hybrid approach.
References:
[1] Siqi Shen, Shun-Yun Hu, Alexandru Iosup, Dick H. J. Epema (2015) Area of Simulation: Mechanism and Architecture for Multi-Avatar Virtual Environments. ACM Trans. Multim. Comput. Commun. Appl. 12(1).

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/