



3.2.2 Measuring NFRs: Metrics
Course subject(s)
3: Non-Functional Requirements
Traditional performance metrics
Traditional performance formalisms from operations research address resource management and scheduling and are applicable also to distributed systems. Such formalisms typically include ways to describe the arrival and progress of jobs through the system and performance metrics that capture the most important stages of this progress and the end-to-end process. All these focus on job-level aspects.
Traditional formalisms also focus on system-level aspects, such as utilization, defined as the fraction or the percentage of resources used by the system to run a single job or the entire workload, and cost, defined as the financial resources used by the system for the same purpose.
The traditional trade-off of (distributed) systems is between job-level and system-level metrics. For example, a system may prioritize reducing the average wait time (AWT) of its jobs, but to do so it would have to have much lower utilization on average than a system that does not prioritize AWT. Conversely, a system may prioritize utilization, but its users would experience long wait-time due to queueing of jobs waiting for resources. Various metrics capture the boundaries of this trade-off, including metrics to capture fairness across jobs and resource waste for utilization
Metrics for complex workloads
More complex workloads include structured jobs, such as bags of tasks and workflows, for which metrics across groups of jobs become useful. These metrics may capture various dependencies between jobs and various system overheads. For example, consider workflows. The makespan of a workflow (MS), is the time elapsed between the arrival and the end of the entire workflow. An important metric is the Normalized Schedule Length, defined as the ratio between the makespan of the workflow and its critical path.
Speedup and slowdown metrics capture the effect of running the workflow in a distributed system, relative to running the workflow in other environments. The metric Speedup vs. One (SU1) captures the speedup due to distributed execution relative to execution on one machine, as the ratio between the makespan of the workflow and the time it takes for its tasks to execute, sequentially, on a single node. The metric Slowdown vs. Infinite (SD∞) captures the slowdown due to running the workflow in the real distributed system, relative to an infinitely large distributed system with ideal communication.
From scalability to elasticity (modern metrics)
Traditional systems focus on scalability, to the point where scalability is considered a grand challenge of computer science. Scalability can be defined as the ability of a system to do more when given more resources. It inherently focuses on the key metric of speedup. However, speedup curves often exhibit an inflection point, or visually a “hockey stick” or “J-shape”, where the system starts exhibiting much worse scaling properties. Thus, it is incorrect to say that a system scales, and better to state that a system scales up to a certain scale, which is taken to mean the number of processors just before the inflection point.
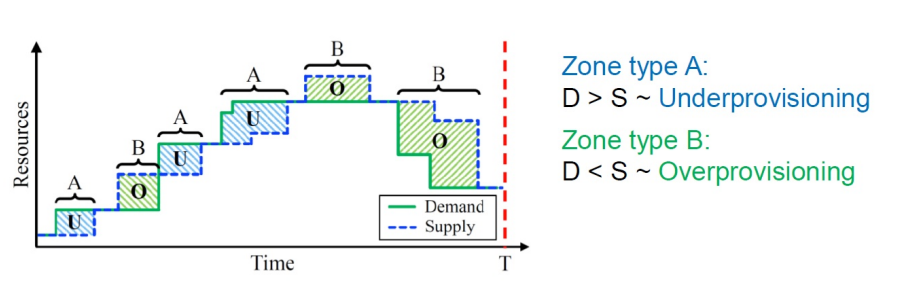
Scaling up or out is not the only way a system can scale. With cloud computing allowing applications and systems to add (provision, lease) or remove (de-provision, release) resources on-demand, scaling down has become equally important in achieving both performance and efficiency (through low resource waste). This leads to the concept of elastic scalability, or the shorter elasticity, which is defined as the ability of a system to do more when given proportionally more resources. Various elasticity metrics measure the degree to which a system can adapt its resources to meet (proportionally) the demand of its application. The figure below depicts the process over time. The decisions taken by the system make the supply curve chase the demand curve as accurately as possible, but still leave inefficient periods when the system becomes underprovisioned or overprovisioned. The concept of Elasticity applies to all cloud operations, including big data deployments in the cloud.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/