



3.2.4 Benchmarking
Course subject(s)
3: Non-Functional Requirements
Benchmarks synthesize for a field a performance evaluation process, a representative workload and a representative (set of) metrics, and a current set of experiments. Benchmarks are then run by many organizations and individuals, to compare the performance of various products and services across the field. The main advantage of benchmarking is that it provides a common approach to performance evaluation, one that is typically cheap to execute. To achieve this, benchmarks are often developed to stress specific aspects of existing systems, aiming to focus the community on a worthwhile goal, e.g., of eliminating performance bottlenecks. The main disadvantage is that a benchmark can only cover the common denominator and can only report a very narrow set of performance metrics. In particular, benchmarks are not good for measuring aspects specific to only a few systems.
There are many kinds of benchmarks, including:
- Micro-benchmarks, which stress specific functions expected to exist in a majority of systems. The functions are narrow and specific, e.g., the exchange (ping-pong) of a pair of answer-response messages in the distributed system, the lease of one resource from a cloud.
- (Micro-)kernels, which use representative hot-functions or core pieces of functionality. A typical example here is LINPACK, the benchmark at the core of Top500. Other examples include the NAS Parallel Benchmarks, the SPEC CPU, and the HPC Challenge benchmarks, which are benchmarking suites comprised of several kernels each.
- Synthetic workloads, which use a selection of key features of workloads, typically either human-driven or statistical. The many TPC benchmarks for database systems, for example TPC-DS13, all select their workloads carefully, assembling a synthetic mixture that could be representative of the field. Typical for these workloads is the inclusion of a workload generator, which creates offline or online a workload according to the input parameters.
- Real-world/realistic workloads use a selection of representative workloads, or their traces, to replay real-world situations across different systems. Changing such workloads meaningfully, for example, for a different scale, is typically challenging.
- Hybrid approaches mix one or several of the previous benchmarking approaches. For example, LDBC Graphalytics is a benchmark for graph analytics that uses kernels (algorithms for graph processing) but generates large-scale, synthetic workloads using an offline workload generator.
An example of a benchmark setup is the Container Scale Benchmark which we developed for determining how container runtime systems like Docker behave on machines when they reach or exceed the available resource limitations. In the particular case, we were interested in how packing machines with additional low-activity containers would affect the few highly active containers, as being able to do so without interference would increase the revenue from the machines operating the container service.
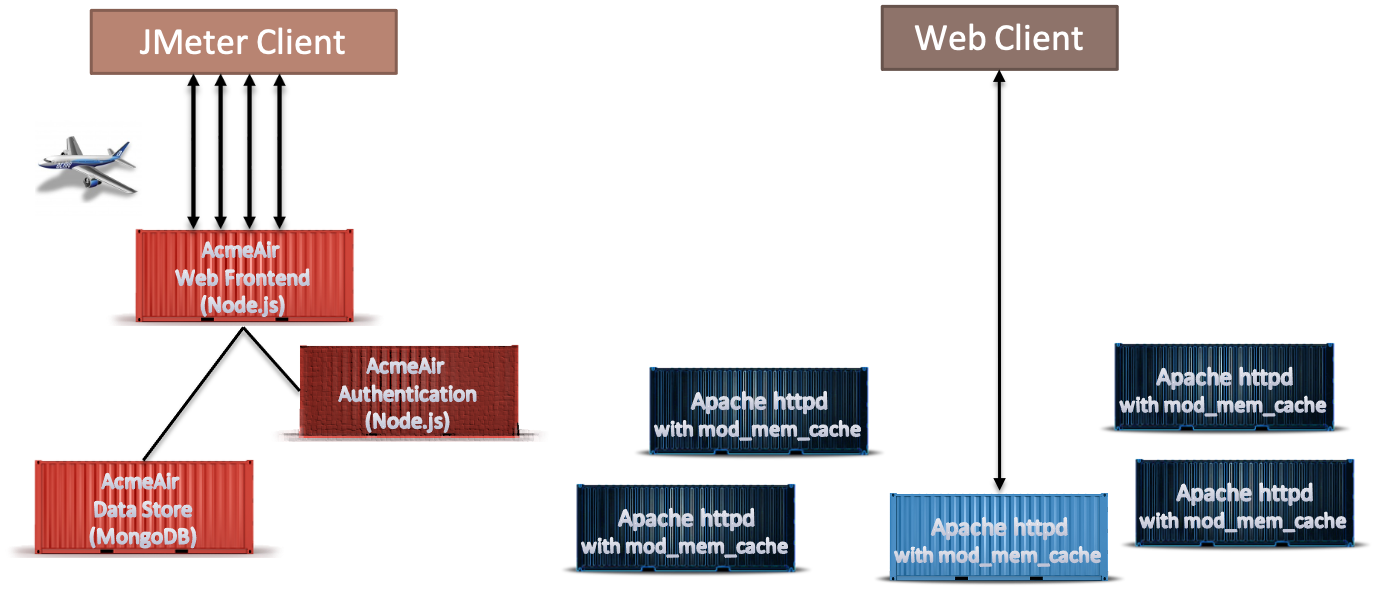
We modelled the active machine by running an existing benchmark, AcmeAir on them, and modelled the rarely active machines as web servers from which we periodically randomly select one and retrieve a static image. You can find the detailed setup and results in our research paper.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/