



3.2.5 Benchmarking Crimes
Course subject(s)
3: Non-Functional Requirements
Benchmarks provide us with a powerful and convenient way of comparing metrics of different systems. We use benchmarks in an attempt to make selection decisions or perceived design or implementation advantages objective. By relying on a common methodology for measuring the metrics, we also try to make the measurements reproducible. However, it is not always clear how to correctly use benchmarks, should they already exist for a given domain. In many cases, however, we have to design and implement our own benchmarks because there are no established ones readily available.
The first and most important question is what to compare against. What we typically want to use is a meaningful reference point. This could be an existing, widely used system, a common methodology that achieves the same goal or anything that would be recognized as a reasonable point of comparison.
In some cases, we know that an optimal solution exists, even if this solution is impractical, but we can postulate this to be the goal standard, the ceiling of our expectations.
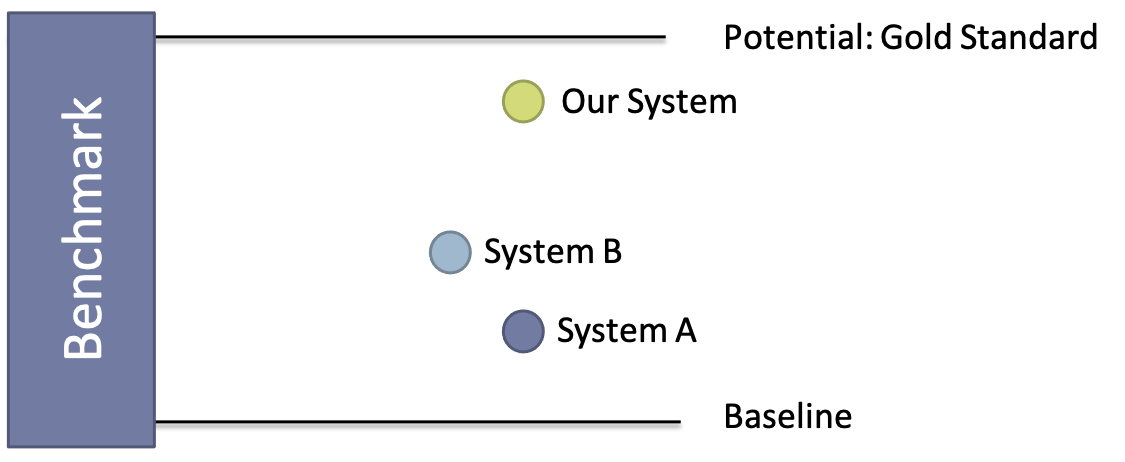
We now pick workloads that we consider representative of the problem domain and run them against the different systems to be able to compare the metrics. In some cases, we have a primary object to compare (e.g., throughput, number of concurrent requests on a given machine, etc.). In other cases, we are interested in capturing many metrics and define our objective later on.
In the big picture of things, having to design both a system and a benchmark for comparison is not ideal because there is always the assumption to overcome that the benchmark is biased towards favoring scenarios for which the system is designed for or for which it is particularly optimized for. Establishing a benchmark as a common ground for an entire community can be difficult in such cases. However, even when used in a restricted setting, we have to be careful with how we use benchmarks and how we report results.

By Copyright UNSW licensed under Creative Commons 4.0 International., CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=125604476
The well-known computer scientist Gernot Heiser has formulated a set of so-called benchmarking crimes that are to be avoided in systems research but we can generalize this to any use of benchmarks.
One example of a benchmarking crime that most people would intuitively agree to be active mischief is the problem of selective benchmarking. For instance, when the benchmark is given as a suite of individual experiments then this is done so for a reason, to provide a comprehensive picture of the behavior of systems under different scenarios. Cherrypicking individual ones or, even worst, cherrypicking individual metrics or experimental results creates a skewed picture which can misrepresent reality and hide deficits of a system.
A more subtle but not less important problem is the selection of an improper baseline. Comparing two related solutions against each other without considering what would be perceived to be the true baseline is equally misleading, albeit sometimes harder to realize.
In summary, just because we use a common benchmark does not automatically mean that we always create objective and reproducible results. Reproducibility is particularly problematic and we will shed light on this problem in the next unit on performance variability. Especially in cases in which we have to design the benchmarks ourselves, we bear great responsibility in the way we use the benchmark and how we report results because the community around us has a reasonable expectation of comparisons to be meaningful and unbiased.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/