



4.2.4 Job Structure in Distributed Systems Workloads
Course subject(s)
4: Resource Management and Scheduling
Workload in distributed systems is comprised of jobs. Jobs are typically diverse: They arrive in the system with or without reserving resources in advance, with or without special requirements beyond merely running, with or without dependencies on the output of other jobs, etc. Scheduling such diverse workloads is a daunting task, which is why modern distributed systems leverage patterns emerging from decades of experience with managing such jobs.
One of the key aspects that distinguishes a workload from a mere collection of jobs is the arrival process, which is how jobs arrive in the system over time. Many distributed systems exhibit temporal patterns that are typical to human behavior, e.g., diurnal peaks or lows in arrivals during work time, leisure time, or commute time; work-day vs. weekend differences; and different arrival processes during seasonal and holiday periods.
Long-term, or for specific clients, workloads may exhibit phenomena such as: (i) the entire workload of a distributed system is often dominated, in terms of resource demand or sheer count of jobs, by just a few or a small fraction of clients, (ii) in a large-scale distributed system, the demand imposed by small clients is highly variable, and (iii) if the system allows for jobs with many tasks running concurrently, the number of tasks will often be a power-of-two. Many of these phenomena cannot be explained by the system’s technical capabilities and require a broader view of causes and effects. For more details on the arrival process and job-related patterns, we refer to Dror Feitelson’s book Workload Modeling for Computer Systems Performance Evaluation (2015).
Another important phenomenon in the workloads of distributed systems is that clients specialize in using just a few kinds of jobs, where the kinds differ mostly in how the tasks are structured and form dependencies toward producing useful outputs. Understanding the main kind of jobs is the focus of the remainder of this section.
Job Types in Distributed Systems

Figure 1. Job types in distributed systems.
We identify in this section job types common in distributed systems. Each job type we discuss is popular and supports many applications common in practice. Figure 1 illustrates four jobs kinds:
Interactive and streaming applications: These job types consist of many kinds of tasks, triggered by time progression or, more commonly, by discrete events. Tasks are often inter-related and need to complete in a pre-specified order, subject to pre-specified constraints on their output (especially, constraints on allowed values). Because the system must respond within a limited amount of time that corresponds to the client’s tolerance to latency, e.g., a few milliseconds for a robotic actuator, a few hundreds of milliseconds for a transaction, tasks are typically short (but many). Examples of applications in this class include interactive simulations, where a complex model mimics a natural phenomenon; remote and robotic control, where typically a physical device is controlled by a remote operator; online gaming worlds and the metaverse, where the virtual world responds to each players’ input; streaming data from sensors or for video-conferencing, either periodically or when interesting situations occur; database transactions, where multiple operations are coordinated to succeed or fail together, and report back to the all clients involved; etc.
Parallel jobs: Originating in classic parallel computing, but stimulated by advances in network capabilities and performance, modern distributed systems often run jobs comprised of many concurrent tasks. For such jobs, multiple execution threads run for large portions of the execution timeline of the entire job, requiring synchronization. When such jobs are small, they may require disaggregating the available resources, e.g., provisioning just some of the thousands of processing cores available in a GPU. When such jobs are large, they may require aggregating resources across multiple physical machines, which is only possible with advanced networking capabilities and, more recently, when the CPU stops being a bottleneck in the system by being replaced by direct pathways between accelerators, as in the work of Brunella, Bonola, and Trivedi (2022) Hyperion: A Case for Unified, Self-Hosting, Zero-CPU Data-Processing Units (DPUs). Applications are abundant for parallel jobs: scientific simulations in climate modeling, bioinformatics, and high-energy physics; engineering simulations in car design, robot manufacturing, bridge engineering; etc.
We focus the remainder of this section on two job types that emerged to prominence together with the modern distributed systems hosting them, bags of tasks and workflows.
Bags of Tasks
Bags of Tasks (BoTs) are jobs including multiple, possibly many, tasks, where the output of the job needs to combine the partial results obtained by each task in part. For such jobs, each task can run independently; it does not matter which task is completed first. As an analogy, consider a bag of seeds; intuitively, we can take any seed from the bag, and only when the bag is empty is the job of seeding complete. BoTs naturally match a variety of applications, including (i) parameter sweeps in engineering, where a model is investigated systematically, sometimes even exhaustively, (ii) Monte Carlo simulations in engineering and science, where simulation starting with random seeds help find answers in fixed time but with limited inaccuracy, (iii) completing loose tasks on available computing resources, as is done in cycle scavenging since the early 1980s (in the Condor project) and in volunteer computing since the 2000s (e.g., on the BOINC platform), to automate operations and reduce waste.
Running a BoT is made easy by dedicated tools, such as Condor. Consider the following example, with which the Condor team has introduced many scientists to the capabilities offered by large-scale, distributed systems. Sue, a scientist, wants to “Find the value of F(x,y,z) for ten values for x and y, and six values for z”. The solution is to run a parameter sweep, with 600 (=10 x 10 x 6) parameter values. With adequate tools, this is easy to do on Sue’s computer. The problem with this solution is that Sue’s computer is good, but only one machine; computing F for one combination of parameters x, y, and z would take about 6 hours; completing all the 600 combinations would take 150 days of uninterrupted computation on Sue’s machine! Instead, Sue can use Condor to leverage the machines made available to all scientists by the SURF national infrastructure for science in the Netherlands.

Figure 2. Launching a 600-task parameter sweep in Condor.
Sue encodes the 600-task parameter sweep for execution in Condor. Encoding it as a BoT is easy to do through a configuration file, as in Figure 2. Sue includes the executable (Executable in the configuration), Input and Output files for data persistence, a folder (Initial_Dir) where data will be read from and stored to, and a command to submit this job to the system queue, for execution. Complex requirements, such as the processor architecture and operating system, and the memory and disk space available on each machine to execute a task, can also be encoded. Because all the tasks are identical in actual computation – they all run sim.exe, but on different data – encoding such a long list of tasks requires only 10 lines of configuration. This is even more efficient for larger BoTs: Only the last line of the configuration file, Queue 600, would need to be adjusted to Queue N, where N is the number of tasks, arbitrarily large.
Upon job submission, which Sue can do by invoking the single and simple command condor_submit <configuration file>, Condor takes over. Sue can monitor the progress of the job, that is, the queuing, running, and completion of each task, but Condor can automate all this by sending messages (emails) to Sue whenever an important event occurs. So Sue can continue work on something else while Condor completes the job.
This approach is not only convenient but also high-performance. Condor can concurrently leverage all the resources that meet the requirements and are available to Sue from the large pool of resources available at SURF. This means that, if the system is not occupied and the tasks can start immediately, the entire job can be completed in only 6 hours; all machines being equal, the job speeds up by a factor of six hundred (600) over running it on Sue’s machine.
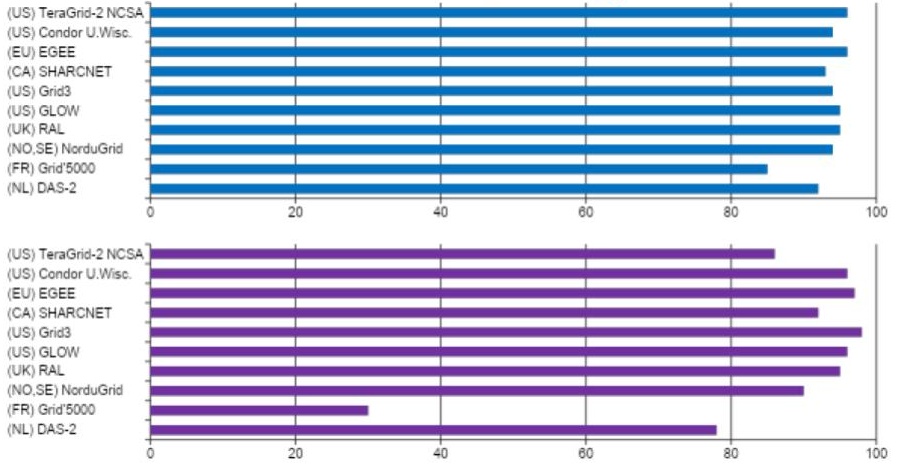
Figure 3. Presence of bags of tasks in various grid computing systems: (top) percentage of all jobs, (bottom) percentage of all consumed resources. Source: Iosup et al. (2006) How are Real Grids Used? The Analysis of Four Grid Traces and Its Implications. GRID.
Because of their ease of use and tolerance to errors by design, BoTs have become the dominant programming model for systems comprised of many resources with cheap, common-off-the-shelf interconnection between resources, as was common for clusters in cluster computing and grid computing (typically, multiple clusters, shared by different operators but operated together for a large group of users). Figure 3 depicts the presence of bags of tasks in various grid computing systems around the world. The top plot depicts the percentage of jobs that are BoTs, from all the jobs observed in each system over a long period (up to years); for all systems in the plot, over 80% of the jobs are BoTs. The bottom plot depicts the percentage of compute resources used for BoTs, from all the compute resources used in each system over the same period as in the top plot; here, except for the research platforms for computer science Grid’5000 and, to some extent, DAS-2, all other systems use over 80% of their compute resources to run BoT jobs. The research platforms also focus their resources on other kinds of jobs, exploring different avenues for scientific purposes. More data and information appear in the article by Iosup et al. (2008) The Grid Workloads Archive. Future Gener. Comput. Syst. 24(7), and the associated data archive.
Scheduling BoTs. There are many approaches to scheduling BoTs, see for example our early comprehensive study [1]. A typical mechanism considers individual jobs, then manages separately individual tasks; this requires a two-level approach, with specialized policies for each level.
Reference:
[1] Alexandru Iosup, Omer Ozan Sonmez, Shanny Anoep, Dick H. J. Epema (2008) The performance of bags-of-tasks in large-scale distributed systems. HPDC 2008.
(Much of the material in this section is based on our 2022 article [1].)
Derived from workflow thinking, a computational workflow describes a process for computing where different parts of the process (the tasks) are interdependent—for example, a task can start processing after its predecessors have (partially) completed and where output data from one task arrived as input data for another. A commonly used type of computational workflow, following a Directed Acyclic Graph model (first analyzed in computer systems by Coffman in the 1960s), does not admit loops; this simplifies execution but limits some of the operations possible within the workflow.
Workflow applications include: (i) complex data pipelines, from data filtering to data aggregation, to complex analysis of instrument measurements, encompassing modern distributed programming models such as MapReduce and Spark, (ii) many machine learning processes based on (iterative) training and inference, including many activities conducted with ML frameworks such as TensorFlow and PyTorch, and (iii) applications created by non-CS scientists, as workflows match many natural and business processes, and feel intuitive to many scientists, engineers, business experts, and people in general, and the visual model of a task-graph can be easier to reason about and program.
![Part of a large microbiome bioinformatics CWL workflow. (Source: [1], diagram adapted from from a corresponding CWL workflow of the EBI Metagenomics project.)](https://courses.edx.org/assets/courseware/v1/4fd6433baff5b433e3dda4240cbcb350/asset-v1:DelftX+MoDS1x+3T2022+type@asset+block/Figure_4-WL-1.jpg)
Figure 4. Part of a large microbiome bioinformatics CWL workflow. (Source: [1], diagram adapted from a corresponding CWL workflow of the EBI Metagenomics project.)
Figure 4 depicts a complex workflow. It consists of many individual tasks, with inputs and output highlighted, and with dependencies visualized as arrows (the tip indicates a “depends on” relationship for the task where the tip ends). Tasks can be developed using different programming models and languages, implemented using different libraries, and deployed with different runtime systems. Some tasks in this workflow are also workflows, further illustrating the complexity that this model can capture.

Figure 5. CWL syntax: (A) and (B) describe the same tool (one task in the workflow), but (B) does so with more detail, showcasing progressive enhancement of descriptions. (C) shows an example of CWL Workflow syntax, for a workflow with multiple tasks. (Source: [1].)
Running a workflow is done through specialized workflow execution tools, such as Pegasus, or tools for comprehensive management of workflows and data, such as Toil. Such tools can run workflows on various resources, in local and remote clusters, and remote grids and clouds. To enable sharing workflows and tasks, to ensure their portability, and – for some outputs – to reproduce and replicate results, the capability of such tools must be complemented by standards to describe workflows precisely, such as our Common Workflow Language (CWL) [1].
Consider the following example, where Sam, a scientist, wants to conduct a new analysis. For his specific analysis, Sam needs to configure a public tool, spoa, for a specific kind of analysis and to define a trivial operation, both part of a more complex workflow shared between multiple organizations. Figure 5 depicts the key steps taken by Sam. First, Sam configures the spoa tool, as in Figure 5 (A). Because this is a preliminary step, and Sam wants it done quickly, the configuration file includes only the minimum necessary, so only a few lines of text. Later, after Sam has tested the configuration, he can add more detail, and after several such iterations the configuration file is depicted in Figure 5 (B). The details include a community-maintained format for the input to the task (label 1 in the figure), so Sam and other scientists can validate the input.
The workflow management system has timestamped and labeled each iteration, so it will be easy later to reproduce the work by Sam and other scientists. The details in Figure 5 (B) include for this purpose a software container (here, based on Docker), which enables portability across the many systems that support containerization, and also specific requirements for running the task (label 3). Requirements can include dynamic aspects such as the amount of required compute resources, the maximum time or deadline to complete the step or entire workflow, etc.
Sam also defines a task to find matches in a text file, using commonly available tools, such as the Linux tools grep and wc. This new task, which itself is a simple workflow combining these tools, is depicted in Figure 5 (C). This task is included in Sam’s much larger workflow for the scientific question he wants to answer, but can be tested and shared independently between different workflow management systems.
We have acquired much empirical evidence that workflows are already very common in large-scale distributed systems, increasingly from the start of the 21st century [2]. Their characteristics have changed much over time, but increasing presence and scale are evident in the empirical data – we did our first comprehensive study in 2008, and through the next ten years until our next study [2] the characteristics indicate these trends.
Scheduling workflows is a complex activity that combines many operational techniques. For example, a scheduler could combine resource allocation, where tasks that can run (because their dependencies have completed) are matched against available resources, with resource provisioning, where the set of resources made available to running tasks for a workflow can change over time.
For resource allocation, algorithms take many possible approaches. One important early result is provided by the policy Heterogeneous Earliest Finish Time (HEFT) [3]. This policy (i) computes the rank for each task, based on average runtime, average data transfer time, and average communication-startup time, (ii) selects tasks in order of descending rank, and (iii) schedules the selected task on the “best” resource that minimizes its actual finish time. By iterating this process, HEFT can schedule all the tasks, with good properties in practice.
Resource provisioning through autoscaling is commonly used in modern distributed systems; see for example our study [4], where the Level of Parallelism, that is, the number of tasks that can be run in parallel, evolving during the execution of the workflow, is computed efficiently before the workflow starts, allowing the system to estimate the maximal number of useful resources at each level. Resources are provisioned from a larger system, e.g., from a cloud.
Reference:
[1] Michael R. Crusoe, Sanne Abeln, Alexandru Iosup, Peter Amstutz, John Chilton, Nebojsa Tijanic, Hervé Ménager, Stian Soiland-Reyes, Bogdan Gavrilovic, Carole A. Goble, The Cwl Community (2022) Methods included: Standardizing computational reuse and portability with the Common Workflow Language. Commun. ACM 65(6): 54-63.
[2] Laurens Versluis, Roland Mathá, Sacheendra Talluri, Tim Hegeman, Radu Prodan, Ewa Deelman, Alexandru Iosup (2020) The Workflow Trace Archive: Open-Access Data From Public and Private Computing Infrastructures. IEEE Trans. Parallel Distributed Syst. 31(9).
[3] Henan Zhao, Rizos Sakellariou (2003) An Experimental Investigation into the Rank Function of the Heterogeneous Earliest Finish Time Scheduling Algorithm. Euro-Par 2003.
[4] Alexey Ilyushkin, Ahmed Ali-Eldin, Nikolas Herbst, André Bauer, Alessandro Vittorio Papadopoulos, Dick H. J. Epema, Alexandru Iosup (2018) An Experimental Performance Evaluation of Autoscalers for Complex Workflows. ACM Trans. Model. Perform. Evaluation Comput. Syst. 3(2). Special Issue with Best-Paper Nominees ICPE.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/