



5.2.1 System Architecture and Programming Models
Course subject(s)
5: System Architecture and Programming Models
Programming Models
Programming Models bridge the gap between the hardware and the layers of software available to applications. By doing so, a programming model usually provides abstractions over concrete hardware and their specific mechanisms, thereby allowing the programmer to focus on the more high-level aspects of application designs and creating portable solutions that are viable on a variety of different hardware. The operational semantics of such abstractions are often simplified compared to the actual hardware and can be formalized more easily.
Examples of such abstractions are models for parallel computation, abstractions over raw memory in the form of specific data structures, and communication models. Programming models can provide one or more of these abstractions at the time, depending on their focus. The most comprehensive programming models provide a full notion of an abstract machine together with its operational semantics.
In comparison, programming languages and APIs provide implementations of these abstractions and allow the algorithms and data structures to be put into practice – a programming model exists independently of the choice of both the programming language and the supporting APIs.
Over the years, various domains such as data processing (batch, graph, streaming), machine learning, storage, relational data management, middleware designs, supercomputers, etc., have come up with their preferred programming model and system architecture. When a field is establishing itself, usually there are multiple competitive models and designs which converge towards a small set of preferred solutions as the field matures.
We will discuss several concrete programming models later in this module.
System Architecture
A system architecture, on the other hand, is the fundamental organization of a system, the components, how they are connected and communicate, and what their individual roles are. As such, the system architecture reflect the physical reality. For instance, a concrete architecture could be built around the way how machines are interconnected in a datacenter, exploiting that machines located in the same rack are typically experiencing higher bandwidth and lower latency in their communication because they are plugged into the same top of the rack switch. We will discuss common system topologies in the following video.
There are common structual elements in system architectures that are frequently used to improve the performance or reliability of the supported applications by creating structural or logical redundancy.
The first element is the load balancer. It can be implemented using a regular machine or a special-purpose network middlebox. A load balancer accepts incoming connections and relays them to a pool of server machines, depending on how high their current utilization is. By doing so, it allows services to become scalable while still be reachable through a common communication endpoint. Load balancing is easy when the service is stateless because in this case requests can be routed to arbitrary machines. Stateful services often have the requirement that all requests from an individual client get routed to the same machine, making the balancing problem more complex and requiring the load balancer to perform the bookkeeping of which user session is handled by which server. Load balancers play a critical role in building highly scalable services such as modern web sites which can handle millions of concurrent user requests per second.
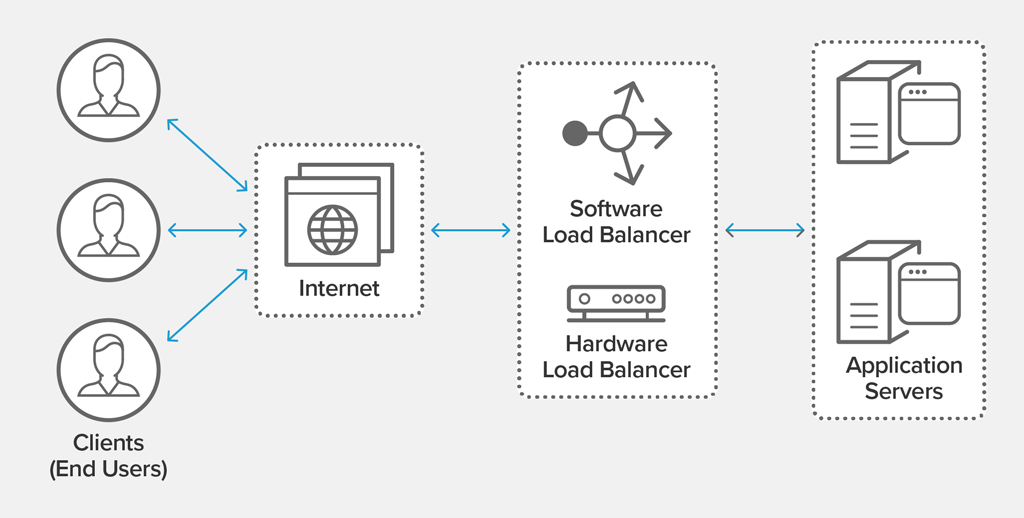
Source: NGINX documentation, https://www.nginx.com/resources/glossary/load-balancing
The second structural element is the cache. A cache provides a local replica of data in order to avoid services to hit a central data store for every request, which would have higher latency and cause scalability issues. These days, caches are typically implemented using memory to store the data, which further reduces the access latency compared to retrieving data from a non-volatile storage device like a hard disk or an SSD. The volatility is not an issue because caches can be considered an opportunistic element, should a data item not be available from the cache then it can still be retrieved from the data store, albeit at higher cost. Often times, the cache only contains frequently accessed data items because its capacity is much smaller than the data store it fronts. Since data items are now replicated between the data store and potentially multiple caches, this poses a consistency issue. Whenever a data item is manipulated, the write must be propagated to the data store as the source of ground truth and the replicated items in the caches need to be invalidated. As a result, caching is most effective in situations where reads are much more frequent than writes.
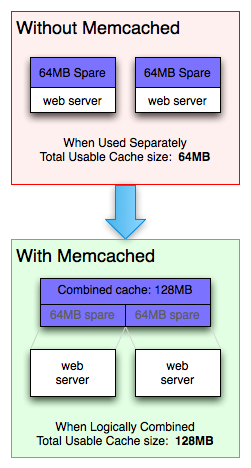
Source: Memcached documentation: https://memcached.org/about
How to Choose?
There are plenty of programming models that people can choose from and some platforms already come with their own programming model. By picking a specific tool or ecosystem, you are implicitly fixing your programming model. As we will see, the programming model can either be aligned with the system architecture and form a good fit, or it can be a suboptimal pairing and create friction and inefficiencies in practice. There is a notion of affinity between Programming Models and System Architecture, and understanding them helps you to build better and more robust systems.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/