



5.2.5 Programming Model Examples
Course subject(s)
5: System Architecture and Programming Models
As discussed, programming models provide abstractions over bare hardware which the programmers can leverage to simplify the system design and, in some cases, achieve non-functional properties. In this unit, we will look into specific programming models and their abstractions.
Pthread
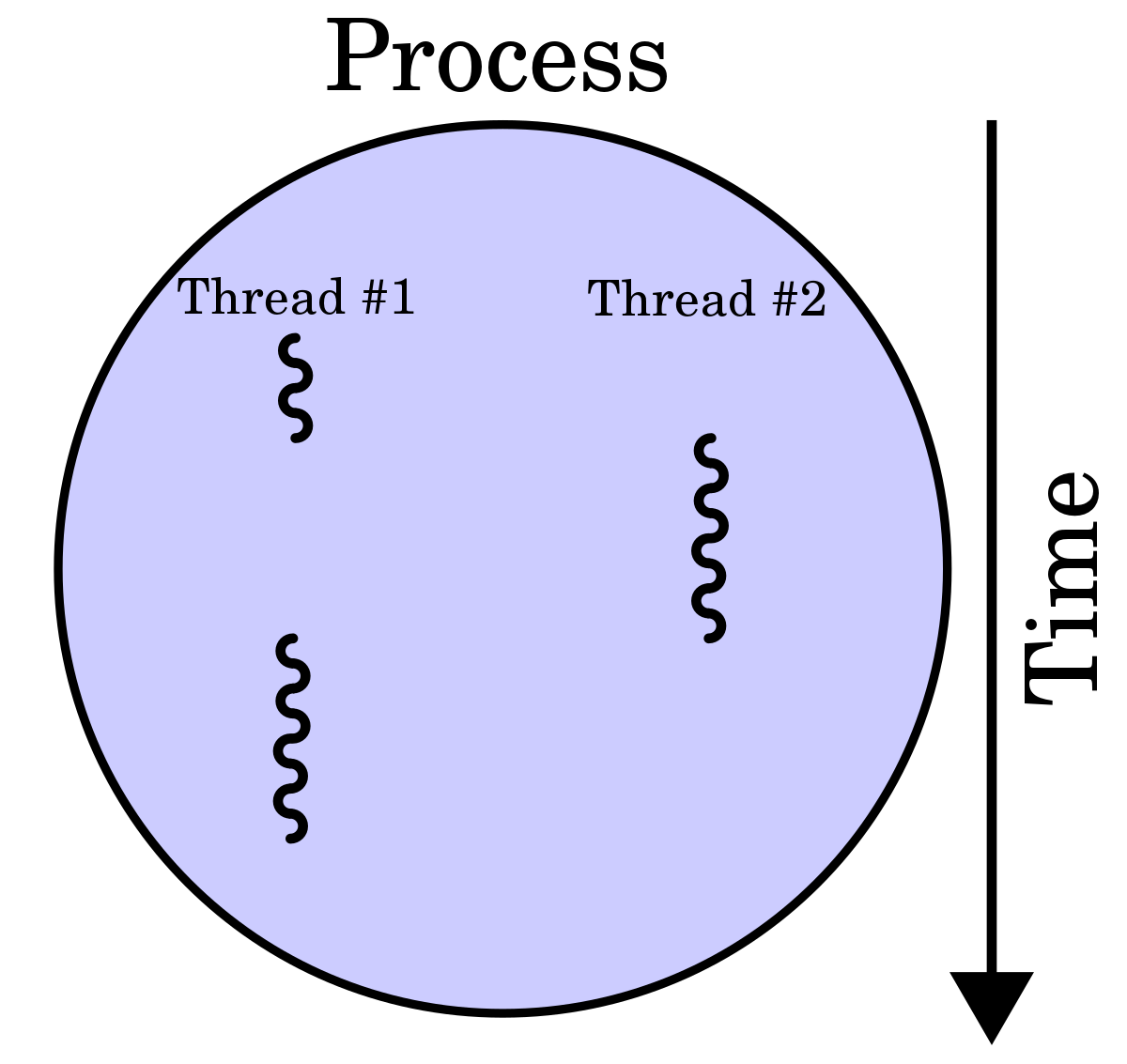
The thread is an abstraction over (parallel) compute. Each thread provides the programmer with a separate unit of execution, thereby allowing programs to leverate the modern multi-CPU and/or multi-core architectures.
POSIX Threads, commonly known as pthread, is one of the implementations of this concept and is used as a programming model for parallel execution. It allows a program to control multiple different flows of work that overlap in time. Each flow of work is referred to as a thread, and creation and control over these flows are achieved by making calls to the POSIX Threads API.
While multi-threading allows a program to run work in parallel, it introduces new challenges such as synchronization. To tackle them, Pthread offers an api for thread creation and synchronization. Keep in mind that pthread is a specification for thread behaviour, and not an implementation. This allows Operating-system designers to implement this specification in a portable manner.
In comparison to processes, threads do not come with their own address space but share a common address space with all other threads of the same process. Therefore, they do not come with an abstraction over memory or state. What they feature, though, is a limited abstraction over communication in the form of condition variables which, in combination with mutexes, can be used to signal between threads. Formally, this is always a broadcast (signalling all waiting threads) or an anycast (signaling one waiting thread) but never a directed communication pattern to a specific thread.
Pthread is a very low-level API for achieving parallel execution. Thus, you have extremely fine-grained control over thread management (create/join/etc), mutexes, etc. Next we will look at OpenMP which builds on the idea of threads but elevates the problem to a higher level.
OpenMP
The challenges of multi-threading in a shared-memory environment can become more complex as the applications grow larger. While Pthread offers fine-grained control but the complexity becomes another hurdle for programmers. OpenMP offers a higher level, more declarative programming model for parallel execution.
With OpenMP, parallelizing code can be as simple as adding a single pragma such as
#pragma omp parallel for
for (i = 0; i < 500; i++)
arr[i] = 2 * i;
to achieve properly multithreaded code with linear speedup. Getting the same performance boost with pthreads takes a lot more work. But of course, it has less flexibility compared to the bare-bone pthreads. However, there is no guarantee that the compiler is able to refactor an arbitrary for loop into a threaded, parallel execution. So it is a trade-off between programming speed and control.
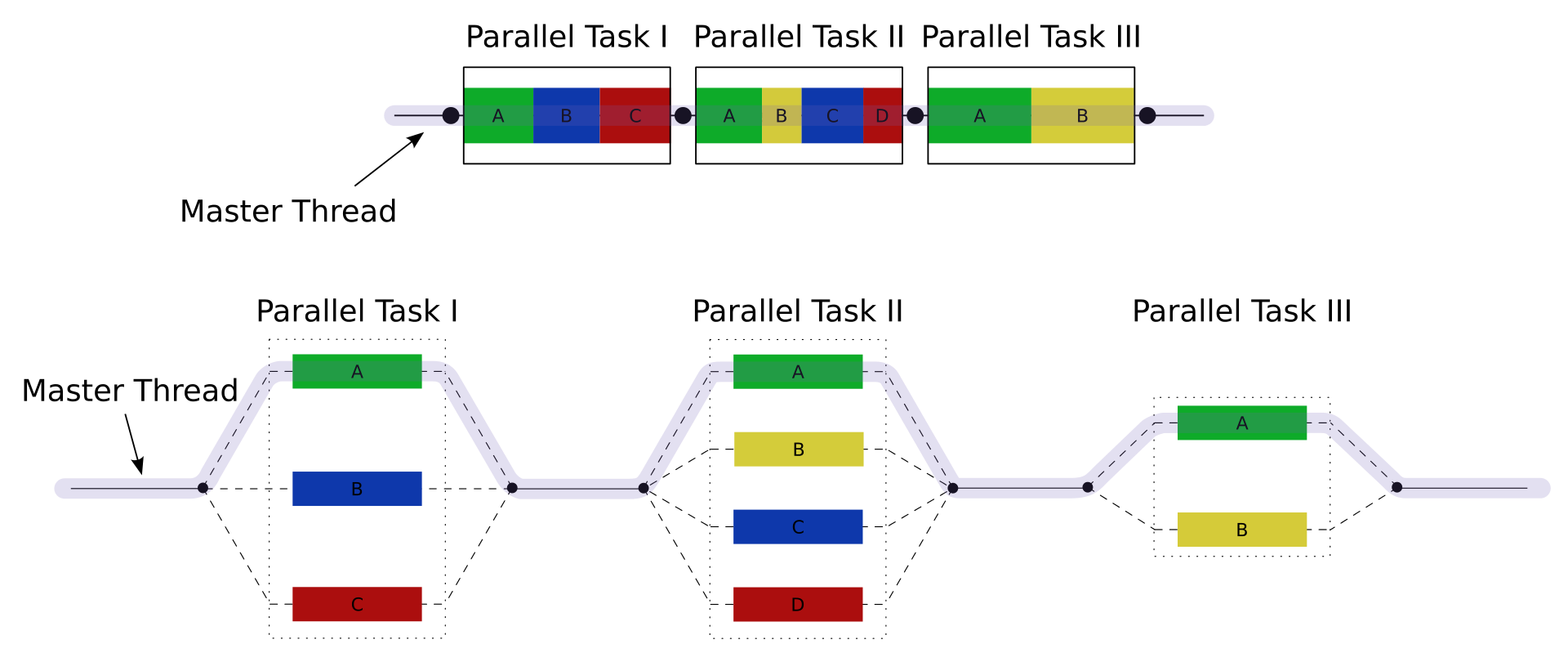
Similar to pthread but at a higher level, the core elements of OpenMP are the constructs for thread creation, workload distribution (work sharing), data-environment management, thread synchronization, user-level runtime routines, and environment variables.
Both pthreads and OpenMP are programming models that assume shared memory, thereby largely restricted to a single machine. Next we will look at MPI, which was designed for devices with distributed memory.
Message Passing Interface (MPI)
With applications getting bigger, more complex and modular, it demanded a programming model that catered for systems with distributed memory. MPI is a programming model for parallel execution through message-passing. It was first designed for distributed memory devices but over time, MPI implementors adapted their libraries to handle shared-memory architecture as well. In this model, every parallel process is working in its own memory space in isolation from the others. Every bit of code is executed independently by every process. The parallelism occurs because you tell each process exactly which part of the global problem they should be working on based entirely on their process ID.
Map-Reduce and Spark
MapReduce is one of the most influential data processing frameworks. It was proposed by Google in 2004 for their internal data processing pipelines. Imagine that you are Google in early 2000, and as the usage and size of the Internet explodes, you need to search and index the vast amount of data online. One natural solution to this problem is to use multiple machines for data processing, thus creating a distributed data processing pipeline. More processing capabilities can be delivered by adding more machines and parallelizing the job on all available resources. However, as different teams implement collection, storage, processing, and searching capabilities independently, they create a jungle of various frameworks. Moreover, instead of using reliable state-of-the-art hardware, Google decided to use commodity off the shelves desktop and server machines. Therefore, at a scale, failures become the norm rather than the exception that needed to be dealt in a standard manner. There was a need for a (semi- )standardized, distributed, fault-tolerance data processing framework. MapReduce is the framework that Google proposed in 2004 in their seminal paper.
MapReduce offers a very simple programming model based on the key-value data type and two user-defined functions: map and reduce. Key-value (KV) is an opaque data structure where a key can be mapped to an associated value. The internals of the mapping and data stored in the key or value are not a concern of the system. The data processing computation is expressed as a single sequence of map and reduce functions.
- A Map function, written by the user, takes an input data and produces a set of intermediate key/value pairs. The MapReduce library groups together all intermediate values associated with the same intermediate key and passes them to the Reduce function
- A Reduce function, also written by the user, accepts an intermediate key and a set of values for that key. It merges these values together to form a possibly smaller set of values. Typically just zero or one output value is produced per Reduce invocation. The intermediate values are supplied to the user’s reduce function via an iterator. This allows us to handle lists of values that are too large to fit in memory
All other details regarding how the large program is distributed and run on multiple machines, how computation proceeds in a case of a failure, how to load balance between available machines, etc. are all hidden from the end user. The user is only responsible for defining Key-Value types, and providing a map and a reduce function to work with KV types. This split of responsibilities is exposed by the programming model and the API of the system.
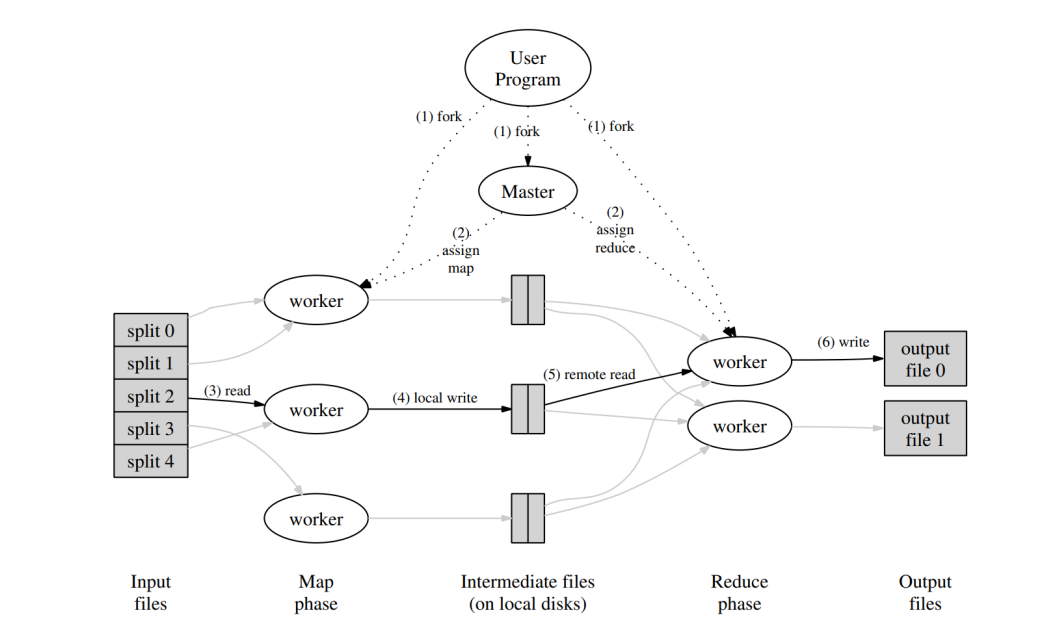
Source: Dean, J., & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1), 107-113. https://doi.org/10.1145/1327452.1327492
By structuring programs into map and reduce operations on a sequential input set, the underlying runtime system can translate the operations into batches which have well-defined lifecycle and can be scheduled effectively on clusters. Should any individual batch fail to compute because of hardware or communication failures, the runtime system can simply reschedule the batch and have the work done by a different machine. While this can cause some delays, the end result is still reliable even in the event of faults.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/