



3.3.2 Computing performance-based weights (2)
Course subject(s)
Module 3. Performance-based weights and the Decision Maker
Recall the example in the previous video, with the calibration and information scores of 7 experts, along with their corresponding performance-based weights.
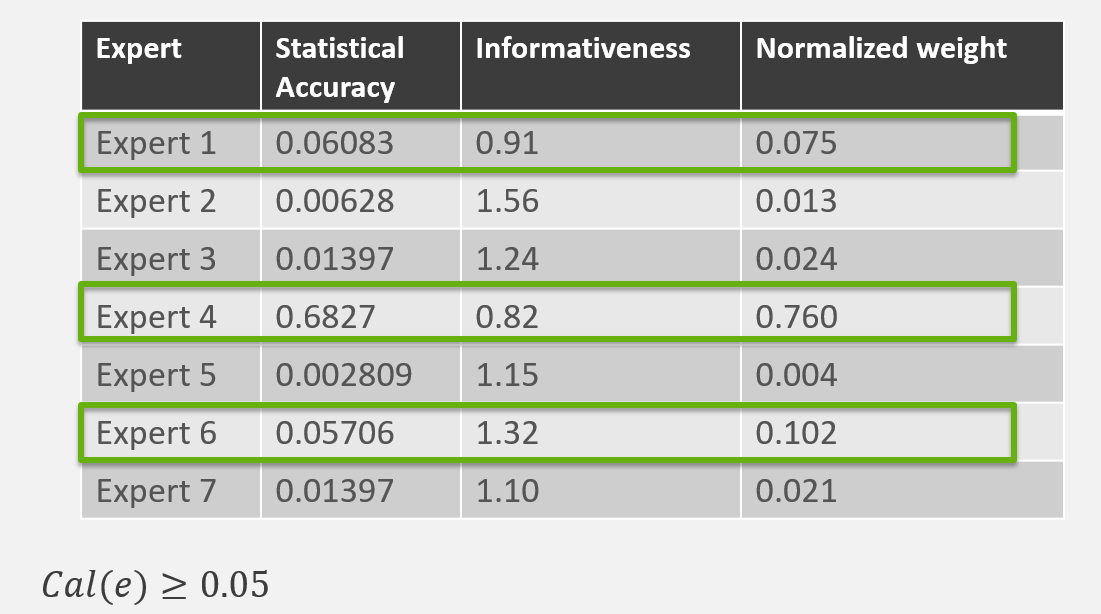
We will see in the next module that it might be beneficial to consider only experts’ assessments which result in a calibration score higher than a given threshold. Since the calibration score can be interpreted as the p-value of a statistical hypothesis test (that the expert’s assessments are statistically accurate), the standard significance level of 0.05 can be used.
In our example, imposing the calibration score to be at least 0.05 leads to the selection of Expert 1, Expert 4 and Expert 6.
How do the weights of these three experts change in this situation?
You have now computed the performance-based weights of the experts, for the chosen significance level 0.05.
Of course other significance levels can also be chosen, say 0.01, or 0.1, etc. The question is then, does one, in fact, need to choose a significance level? And if so, then which one should one choose, or that is, based on which criterion?
We will see later in this module how it is possible to choose optimized weights!

Decision Making Under Uncertainty: Introduction to Structured Expert Judgment by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/decision-making-under-uncertainty-introduction-to-structured-expert-judgment//.