



4.2.5 Scheduling Architectures for Distributed Systems
Course subject(s)
4: Resource Management and Scheduling
Next to the mechanism and policy, a third important concept for scheduling in distributed systems is the scheduling architecture: how the scheduling components are arranged to work with each other toward taking and enforcing scheduling decisions.
There are many possible architectures, but the main classes discussed in this section are (i) architectures for scheduling in single-cluster systems and (ii) architectures for scheduling in multi-cluster systems. The concept of a cluster is common practice, denoting the grouping of a large number of resources, typically similar at least in what concerns the scheduling interface, under the same operational authority. A cluster in a data center is currently constructed physically as a few tens of powerful but common computers (machines, nodes), placed in a rack, interconnected with a good but common network, accessible from the rest of the data center through a top-of-the-rack switch or router.
The remainder of this section details scheduling architectures for single- and multi-cluster systems.
Single-Cluster Scheduling Architectures
Among the common single-cluster architectures, we distinguish two extreme designs: the centralized approach governed by a head node, of which Kubernetes and VMware cluster services are modern examples, and the decentralized approach, of which Condor (and its variant, Mesos) is a canonical example.
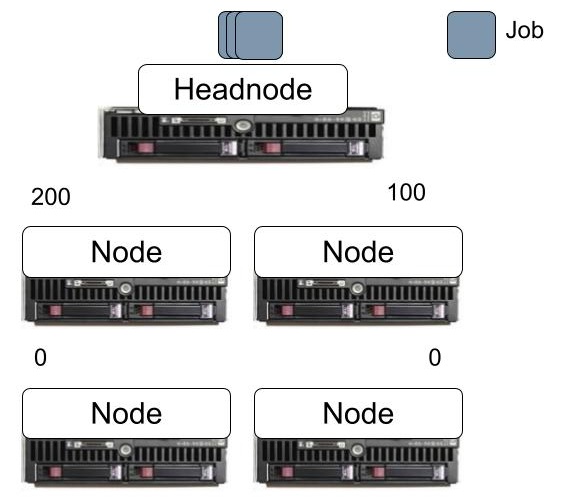
Figure 1. The centralized approach with a head node to manage the cluster.
Centralized approach to managing a single cluster: Figure 1 illustrates an architecture where the central head node receives all jobs and governs how they are distributed to each node. The head node runs a scheduling mechanism and policy, typically queue-based. In the figure, the head node decides to allocate the first 300 incoming jobs without load balancing: The top-left node receives 200 jobs for execution, the top-right node receives 100, and the rest of the nodes are not involved in running these jobs. This can have different consequences: in terms of availability of resources, it leaves half the system available for an important job about to arrive but also does not fully utilize the resources.
Advantages: Overall, the system is not overly complex. A central head node simplifies implementing and deploying in production dynamic resource scheduling and other complex operational techniques, for example, scheduling tasks and jobs with affinities, fair-sharing, migrating tasks and their state, offering high-availability services especially with active-active replication, etc. On the client side, the single, central head node simplifies the resource selection problem – only one entry point exists in the system.
Disadvantages: A centralized approach introduces a Single Point of Failure (SPoF) and a Single Point of Authority (SPoA), both of which can be undesirable for operations across multiple stakeholders.
A more difficult aspect to analyze is the scalability of this system: Although the nodes work independently, the head node needs to take decisions across all jobs and nodes, and often these decisions have consequences for other decisions, so the head node forms a natural bottleneck. Even if the head node is designed as a distributed system, this bottleneck will not be easy to remove. In practice, large clusters of homogeneous resources can run to tens of thousands of nodes, spread physically across many racks. Still, scalability and other issues can limit many clusters to just a few up to a few tens of nodes.
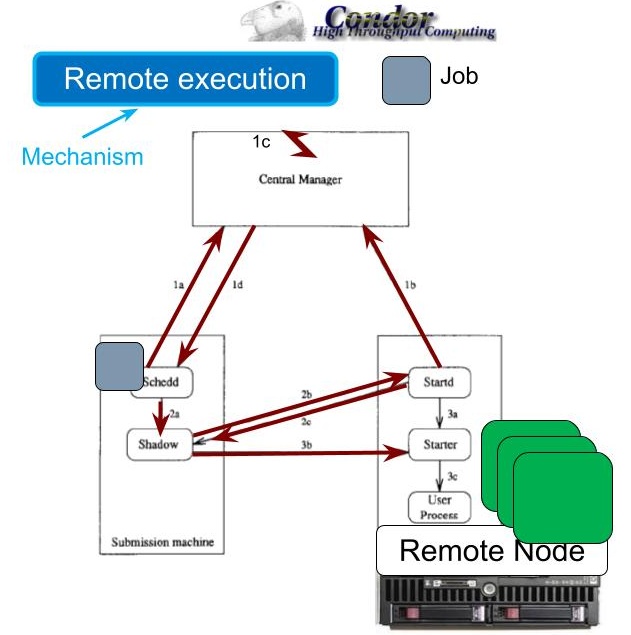
Figure 2. The decentralized approach to managing resources in Condor. (Source: [1].)
Decentralized approach to managing a single cluster: Figure 2 illustrates the architecture introduced by Condor. There are three key components, placed on each submission machine, each remote machine, and a central matchmaker (manager). The submission machine is where the client submits the job. Independent operators provide the remote nodes, which are machines that can run jobs. The centralized matchmaker receives ClassAds from both jobs and nodes, and finds good matches between them. The architecture is decentralized even if the matchmaker is a central component, because the main operation of the system, and especially the job execution, takes place independently of the central manager.
The basic operation of this architecture includes the following steps:
1a. The jobs send ClassAds to the matchmaker, advertising their need for resources. These needs can be complex, specifying the processor architecture, amount of resources, and other information.
1b. Concurrently with step 1a, remote nodes send ClassAds to the matchmaker. Similarly to the ClassAds of jobs, the remote nodes can offer detailed information, including their processor architecture, amount of available resources, and other information.
1c. The matchmaker finds matches between jobs and machines, which is effectively a scheduling decision waiting for its enforcement.
1d. The matchmaker notifies the submission machine of the match.
2a. The submission machine starts a shadow process that represents the remote job on the execution machine, allowing the process to interact with the matchmaker, to start the scheduling process for another job on the submission machine.
2b/c. The submission machine contacts the remote node that was identified as a match, and receives an agreement from the remote node to execute the job.
3b/c. The remote machine starts the job. The remote node can have many more resources available than the submission machine, and the remote node can stay active long after the client has disconnected from the submission machine. As depicted in Figure 2, there may be several jobs running concurrently on the remote node.
Advantages: The central matchmaking sub-system enables complex descriptions for jobs and nodes, and simplifies implementing and deploying core scheduling decisions in production. On the client side, the resource selection problem is managed automatically.
The most important advantage of the Condor architecture is that, beyond the scheduling decision, the system scales much better than the head node approach, because each submission machine – in some systems, each client’s laptop can act as a submission machine – connects directly to each remote node, effectively distributing the enforcement of scheduling decisions.
Disadvantages: Overall, the system is more complex than the head node approach. Although more limited, the SPoF and SPoA issues of the head node approach still exist.
Reference:
[1] Thain, Tannenbaum, Livny (2005) Distributed computing in practice: the Condor experience. CCPE 17(2-4): 323-356 (2005)
Multi-Cluster Scheduling Architectures
Among the multi-cluster scheduling architectures, we distinguish (i) fully decentralized, independent clusters, where clients pick clusters on their own as a form of observational scheduling, (ii) the centralized meta-scheduler, and (iii) fully decentralized, load-sharing clusters.
We generalize the problem of managing across multiple clusters by considering the notion of site. Each site consists of some, possibly many resources, possibly belonging to multiple physical clusters located in close geographical proximity and operating under the same administrative control; and/or some, possibly many local users, for whom the site has a special duty of care relative to the other clients in the system.
Each site also has an internal scheduling architecture, which manages local jobs. This architecture can be one of the two we introduced earlier for single-cluster scheduling.
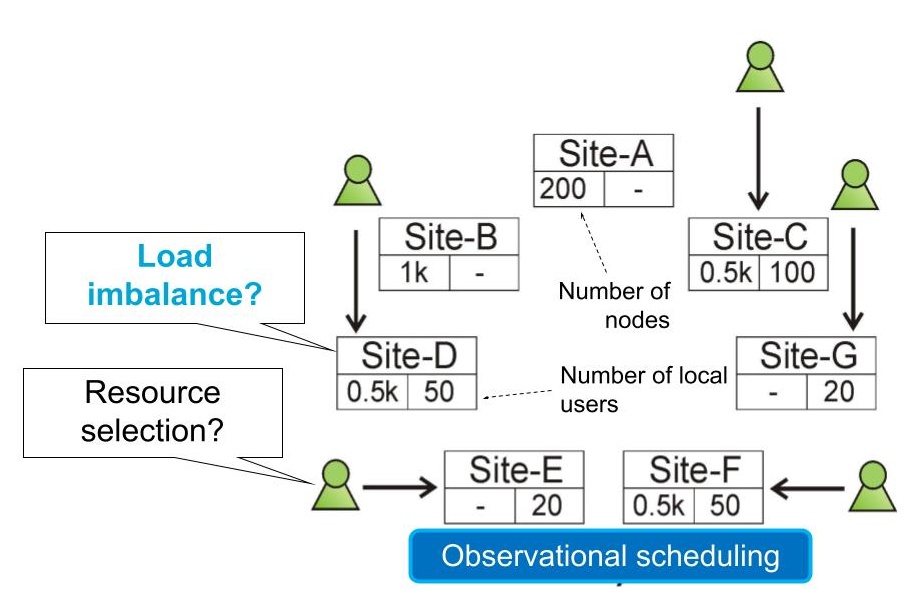
Figure 3a. Observational scheduling across multiple sites.
Fully decentralized, independent clusters (Figure 3a): In this architecture, each site can be contacted by each client; local users get priority and in general more rights over resources than other clients. Multiple sites operate, but there exists no coordination mechanism between clusters, so users select the target site for their jobs on their own. In Figure 3a, we see many configurations of such sites, of which Site-A and Site-B have many nodes but no local clients (they act like generic clouds, possibly competing for clients), Sites-E and -G have no nodes but host 20 local users each (institutions without computing infrastructure), and Sites-C, -D, and -F have both local nodes and local users (act like cooperating institutions for which there is no personnel to manage the shared infrastructure).
Clients selecting sites leads to observational scheduling, where each client observes the state of each site and decides, independently from the other clients, where to submit the next workload part.
Advantages: Generally, this architecture is very easy to set up and is quite common in practice. Especially when sites without local clients have many nodes, which corresponds to clouds operated by Amazon, Microsoft, Google, and others, clients have plenty to choose from.
Disadvantages: The problem of resource selection can be daunting. Comparing resources and costs between different sites can be difficult, and sales tiers and marketing campaigns can make this choice even more difficult.
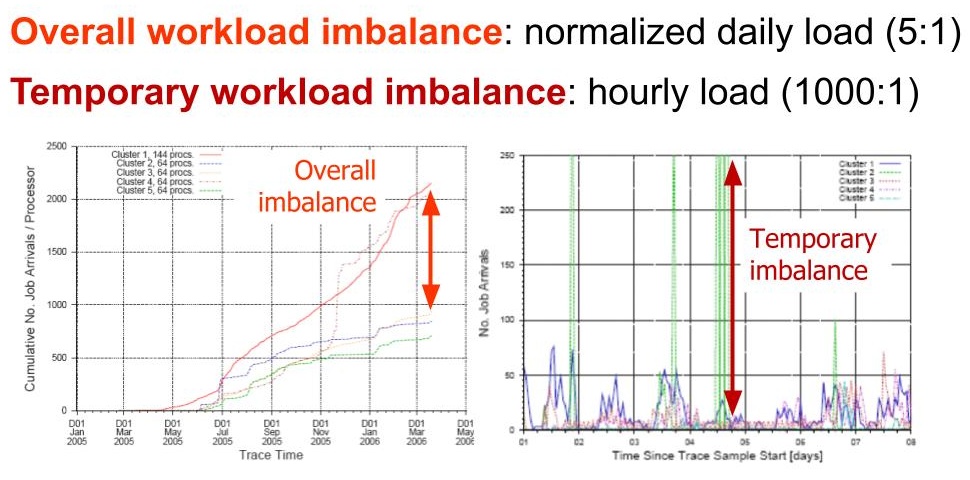
Figure 3b. The performance of observational scheduling, in practice. (Source: Alexandru Iosup, Dick H. J. Epema, Todd Tannenbaum, Matthew Farrellee, Miron Livny (2007) Inter-operating grids through delegated matchmaking. SC 2007: 13.)
A special disadvantage occurs when the workload is large relatively to the overall available capacity, a situation more likely to occur when some of the sites are much smaller than others. Here, observational scheduling can lead to many users making the same choice, which may be rational from each perspective but lead to a bad outcome in the system altogether. Figure 3b depicts an extreme case of observational scheduling. Although the sites in the system are relatively similar, and only one site is larger than the others (by a factor of about 2.5), clients repeatedly identify some sites as the most useful and, together, overload these sites. The overall system experiences high workload imbalance between different sites, both temporary (during minutes or hours) and overall (over the year-long period we study). The temporary imbalance reaches a ratio above 1000:1, between the workload submitted to the busiest site and the least loaded, which overloads one site while many available resources exist in the system. The overall imbalance exceeds the size imbalance between the largest and the smallest sites; worse, one of the smaller sites receives much more workload than its similarly-sized peers.
We conclude that observational scheduling can lead to many unwanted effects.
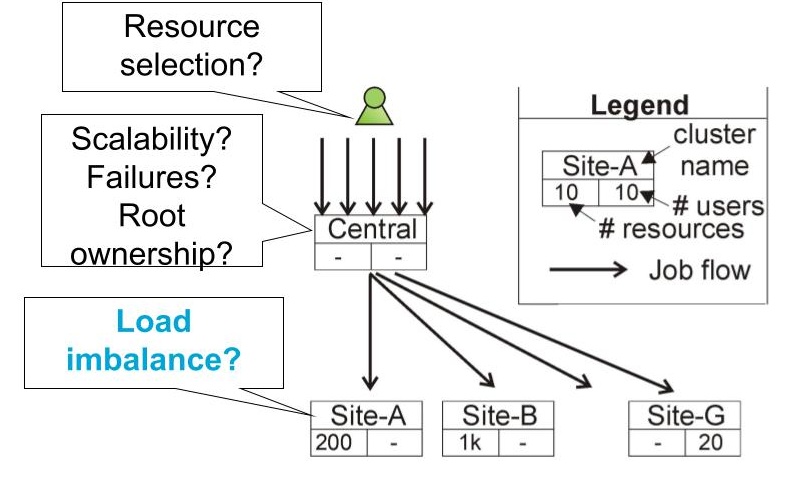
Figure 2. Centralized meta-scheduler architecture.
The centralized meta-scheduler (Figure 2): This architecture addresses some of the issues posed by the independent operation of clusters in the observational scheduling, by interposing a centralized meta-scheduler between clients and sites. A more complex architecture can be achieved by further interposing centralized meta-schedulers between existing meta-schedulers and groups of sites, effectively forming a hierarchy of meta-schedulers and site schedulers, where the site schedulers form the leaves of the hierarchical tree.
Advantages/Disadvantages: By design, this architecture alleviates the resource selection problem and its consequences, but introduces the same issues we observed for the centralized single-cluster scheduler. Especially the SPoF and SPoA are even more important challenges for this environment, because of the increased scale and more complex administrative structure.
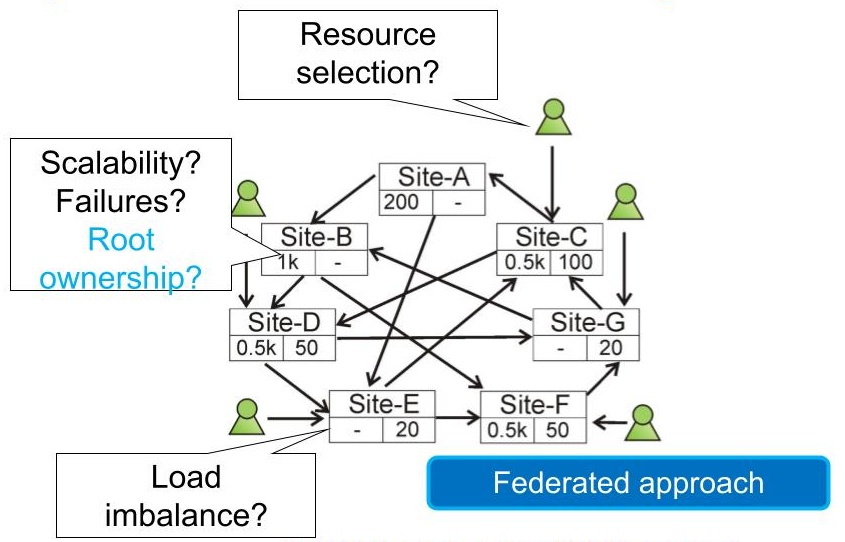
Figure 3. Architecture with fully decentralized, load-sharing clusters.
Fully decentralized, load-sharing clusters (Figure 3): This architecture tries to alleviate the challenges raised by any SPoF or SPoA in the system, by enabling each site to share load with each other site, peer-to-peer. Sites can federate the execution of some jobs, for example, when sensitive, large, or otherwise difficult to move data resides with another site.
Advantages: By design, this architecture does not have a SPoF or a SPoA. Also, clients do not have to worry about the resource selection problem, because the peer-to-peer load-sharing (when done right) can balance the load where it’s needed; approaches for load sharing with good theoretical properties have been studied well through the 1980s, including the seminal article of Yung-Terng Wang and Robert J. T. Morris (1985) Load Sharing in Distributed Systems. IEEE Trans. Computers 34(3).
Disadvantages: Enabling collaborations between each site, particularly enabling jobs from any user to run at any site, is a daunting administrative challenge. For global-sale systems, additional limitations may emerge from the socio-legal environment; currently, it is not possible to easily run tasks for American clients in China, or to run jobs on behalf of North Korea on European servers at all.
In practice: Many practical approaches combine these architectures, for example, by allowing a federated approach between a core group of sites, enabling load-sharing unidirectionally toward some sites, or bursting excess load to a nearby cloud.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/