



5.2.6 Layering
Course subject(s)
5: System Architecture and Programming Models
In practice, most production systems are layered. This means you are dealing with a fractal system because every component is a distributed system by itself and that means those components internally have their own Programming Models, System Architectures, and Topology and there is a lot of complex interaction between the different layers. Just because two components live in an ecosystem does not necessarily mean that they share a common programming model or a common abstraction and rely on the same system topology. So it is important to understand how different components work and which combinations of components make sense from a high-level architectural point of view. Consider the following architecture for a streaming big data application:
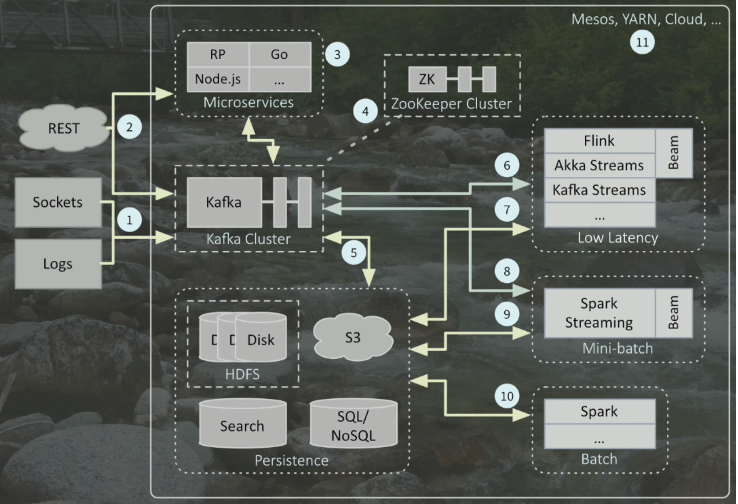
Wampler, Dean. 2017. “Fast Data Architectures for Streaming Applications.” GOTO Conferences
Typically you have a starting point ➀ where data comes in. They could be classic RESTful requests ➁, e.g., someone authorizing a credit card transaction, which is typically handled by microservice toolkits written in Go, Node.js, etc. ➂ Or they could be large volumes of data coming in from outside through Sockets, such as IoT sensor data, or even internal Logs, for example, the click-stream logs for your website that can be processed for usability studies.
The backbone of this particular architecture is the Kafka cluster ⑤. The streaming data usually ends up there due to the fact that Kafka is an excellent tool for ingesting data in a reliable and durable way. The data typically resides there for at most 7 days, so it is not really intended for long-term storage. Through message queues and topics, Kafka allows us to connect different services in our architecture in a much cleaner way, because it removes the tight coupling resulting from directly connecting services to each other. Instead, by putting Kafka in the middle, it gives us a common protocol for communication between different services as well as durability since if a service goes down, the data is still in and can be read from Kafka. Additionally, Zookeeper ④ is another useful service in our system for reliability purposes and is required for Kafka by default.
Now that we have made sure our data is safe and sound, the next step is processing that data. As a designer, you have access to a variety of different tools (⑥⑦⑧⑨⑩) for batch and streaming processing, each with their own pros and cons. Which one you should choose depends of course on the use case and requirements. For instance:
-
- How low is the latency requirement? We cannot get under 200 milliseconds, using Spark Streaming. Perhaps the most prevalent low latency (~10 milliseconds) engines are open-source projects Apache Flink, Akka Streams, and Kafka Streams. But if you can afford minutes, then batch processing makes a lot more sense because the downside of streaming engines is that they are required to run for an extensive amount of time which can run into contingencies in addition to the ups and downs of the scalability requirements. Batch jobs on the other hand, only need to be effective for a few minutes or hours they are running.
- What is the data volume? For example, if you have around less than 10,000 events per second, you might not need a streaming engine at all since there are several tools that can handle classic REST requests at this scale. Once we get to 100,000 events per second, then having bottlenecks in the system that limit the scalability becomes a factor (refer to Amdahl’s law in section 3.2.3). And once we are at the scale of 1,000,000 events per second, then that is where streaming engines shine because they partition the data and process them in parallel.
- Integration with other tools? Typically, well-known engines already have some form of API to talk to other prevalent tools, for example Kafka Streams to S3 object store. But it is generally a good idea to select an engine that can integrate well with other tools in your particular pipeline.
- How do you want to process the data? For example, if you want to write SQL queries, then that limits your tools because SparkSQL is the most mature SQL option, something which other engines like Akka Streams do not support at all.
For Persistence ➄, again, there is a plethora of options. For example writing to distributed file systems such as HDFS, or object stores like S3, elastic search, or traditional databases.
A major benefit of having modular and layered architectures like this is that it enables us to consider different Deployment scenarios ⑪. You could use resource management frameworks such as Kubernetes, Mesos and Yarn, or we could use the resource management tools of your selected cloud provider.
As we have shown in this example, complex applications are often composed out of layers of different systems which can each come with their own Programming Model and even System Architecture. The Programming Models can co-exist and do not interfere with each other as long as the APIs between the systems are effective at the task. Similarly, different System Architectures can co-exist unless non-functional properties demand tighter integration, for instance, to exploit locality in big data processing like MapReduce over distributed storage systems like HDFS.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/