



6.2.2 A Theory of Distributed Ecosystems
Course subject(s)
6: Distributed Ecosystems: Putting It All Together
Conceptually, distributed ecosystems are the highest level of abstraction we currently know in the field. They are inextricably linked to distributed systems, but ecosystems allow us to further understand, model, and explain reality as we can observe it already.
By understanding more about distributed ecosystems, and in particular by having, next to clear applications, a basic theory that provides a definition, a set of tools that allow us to analyze specific details in the operation of distributed ecosystems, and working approaches to solve problems in the field where experiments can test solutions and solutions can be checked also by others, we could understand how distributed ecosystems work, improve their operation, tame their complexity and variability, increase their generality, create new organizations, products, and services around distributed ecosystems, and more generally address the societal challenges we introduced in the previous section.
Definition of Distributed Ecosystems

Figure 1 depicts a structured definition of distributed ecosystems.

Figure 1. Distributed ecosystem, a definition.
Derived from an early definition we introduced [1], a distributed ecosystem is…
A group of two or more constituents (components), often heterogeneous, so performing different functions and operating with different behavior. In contrast, a distributed system typically consists of homogenous components.
Each component is a regular (computer) system, a distributed system, or a distributed ecosystem. A distributed ecosystem may include components that are non-distributed systems, and possibly are not computer systems. Most importantly, a distributed ecosystem may include components that are themselves distributed ecosystems, e.g., a large scientific application may include the ecosystem of a major serverless or even entire cloud platform, for example, Amazon Web Services or Microsoft Azure.
Constituents are autonomous, meaning they can make their key operational decisions, e.g., whether to stay in the system, or to evolve, without input from other components in the system.
As for distributed systems, the system structure and organization ensure the responsibility of the distributed ecosystem. However, this responsibility extends that of distributed systems: distributed ecosystems complete diverse functions or provide services at many granularities, thus supporting various applications. There is much emphasis on supporting non-functional requirements which, as we will see, greatly exceed what we expect of a typical distributed system. An emerging property of distributed ecosystems is keeping the client in the loop, which has become an ethical imperative in the 2020s – explaining system-level decisions can reduce technological anxiety, provide transparency and thus help achieve (perceived) fairness, etc.
Although we expect short-term dynamics to be challenging in distributed ecosystems due to diversity and scale, their long-term dynamics, emergent behavior, and evolution are particularly new. The growth of a distributed ecosystem can lead to networking effects, where an ecosystem derives additional value from the presence of more users (Metcalfe’s law). Exponential growth is expected for successful technological ecosystems when they emerge. Ecosystems evolve: they change and lose parts, grow in scale or function, develop new behaviors, etc. A part may become technologically obsolete and be replaced, yet the ecosystem could continue functioning (e.g., magnetic-core memories replaced with RAM based on semiconductors and integrated circuits). Emergent behavior often appears in distributed ecosystems, with phenomena such as observational scheduling leading to component overloads, social behavior leading to system overload (e.g., all members of a community submit workload the month before the deadline of a conference, and almost nothing immediately after), and toxicity between clients leading to diminished value for particular ecosystems (e.g., misinformation on social networking platforms, bad language and verbal abuse in online gaming).
Short- and long-term dynamics can be introduced in a distributed ecosystem by its components, as they automatically learn about their environment, reason about it, and pursue higher-level goals; in other words, they act as self-aware systems [1]. Recovery, auto-scaling, workload prediction, energy awareness, self-diagnosing and self-troubleshooting problems, and self-discovery of application topology are some of the operational techniques distributed ecosystems use to this end.
How do ecosystems appear? Computer ecosystems often appear naturally, through a process of evolution that involves the accumulation of technological artifacts in intercommunicating distributed systems and hierarchical distributed systems, as organizations pursue solving increasingly more sophisticated problems and/or radical efficiency measures.
When is a distributed system not a distributed ecosystem? From our previous work [1], even some advanced distributed systems do not qualify as ecosystems, including (i) many audited systems avoid including multi-party software and components that are too autonomous, (ii) legacy distributed systems, built monolithically or with tightly coupled components, (iii) legacy systems developed with relatively modern software engineering practices, but which do not consider the sophisticated non-functional requirements of modern stakeholders, (iv) systems developed for a specific customer or a specific business unit of an organization, which now need to offer open-access for many and diverse clients.
What does the definition imply about the distribution property of distributed ecosystems? Relatively to distributed systems, distributed ecosystems can be said to possess the property of super-distribution, which means simply that the properties of a system where components are much larger and more complex than a regular distributed system are much more impactful, but likely much more difficult to analyze and ensure. Thus, for each property you learned so far, a super-property exists: super-scalability instead of scalability, etc. (This is a paraphrasing of the old adagio that every new order of magnitude in scale and complexity leads to a different problem in computer systems; a 1998 version of this was part of the original Distributed Computing Manifesto that underpins the market-leading distributed ecosystem built by Amazon Web Services [3] and a 1999 version appears in Jim Gray’s Turing Award speech [4]).
References:
[1] Alexandru Iosup, Alexandru Uta, Laurens Versluis, Georgios Andreadis, Erwin Van Eyk, Tim Hegeman, Sacheendra Talluri, Vincent van Beek, Lucian Toader (2018) Massivizing Computer Systems: A Vision to Understand, Design, and Engineer Computer Ecosystems Through and Beyond Modern Distributed Systems. ICDCS 2018.
[2] Samuel Kounev, Jeffrey O. Kephart, Aleksandar Milenkoski, Xiaoyun Zhu (2017) Self-Aware Computing Systems. Springer International Publishing, ISBN 978-3-319-47472-4. Esp. Ch. 1, The Notion of Self-aware Computing, and Ch. 20, Self-awareness of Cloud Applications.
[3] Werner Vogels, Distributed Computing Manifesto, Amazon internal document 1998, published as tech blog in Nov 2022.
[4] Jim Gray (2003) What next?: A dozen information-technology research goals. J. ACM 50(1).
Tools to Analyze the Operation of Distributed Ecosystems
We consider in this section a short, non-exhaustive list of tools to analyze the operation of distributed ecosystems. The tools presented here focus each on a large, but still relatively detailed problem, and propose for it a solution.
The Pyramid of Performance Metrics for Distributed Ecosystems (Figure 1)
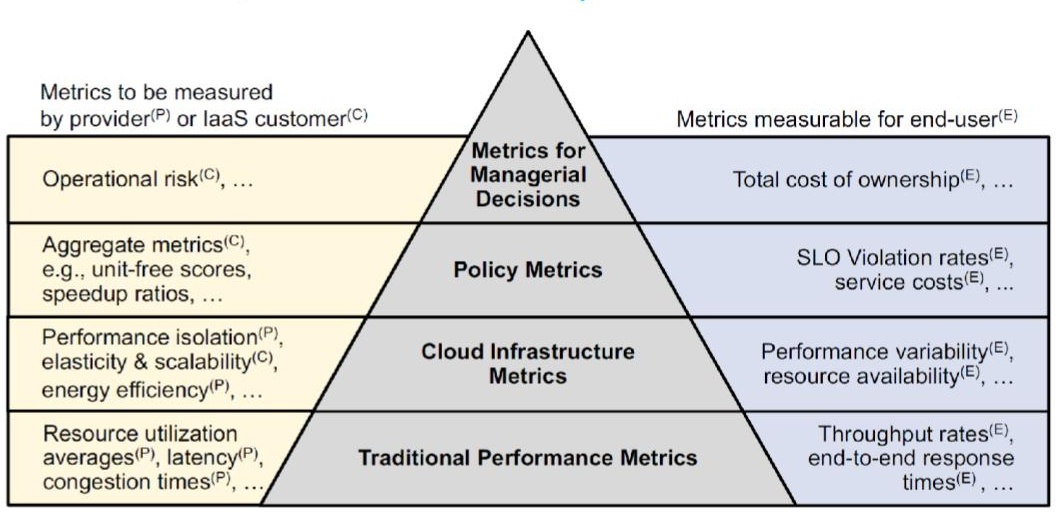
Figure 1. A layered view of performance metrics for different stakeholders in the data center ecosystem. (Image source: [1].)
Problem: Traditional performance metrics offer important insights into the operation of (distributed) computer systems. As the scale of both resources and applications increases, and especially as distributed ecosystems become the operational norm, traditional metrics are increasingly complemented by other kinds of performance indicators (metrics, for simplicity). These new metrics help quantify the operation of the entire infrastructure, capture how well policy decisions are supported, and help make managerial decisions. How to understand the many emerging metrics for distributed ecosystems?
Solution: The layered view provided by Figure 1 contrasts metrics for different stakeholders, across the traditional, cloud, policy, and managerial concerns. This layered view was jointly developed by a team from the SPEC RG Cloud Group, led by Nikolas Herbst.
Operational Data Analytics for Distributed Ecosystems (Figure 2)
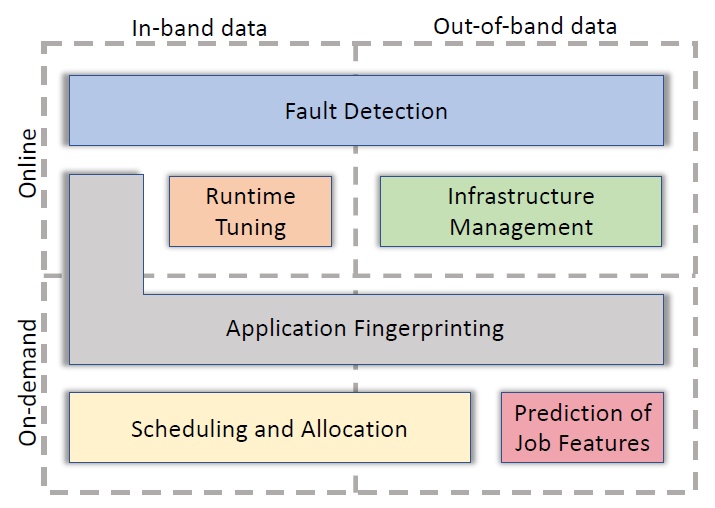
Figure 2. ODA applications. Taxonomy proposed by Netti et al. [2b]. (Image source: [2b].)
Problem: As the scale and complexity of distributed ecosystems, and in particular of those ecosystems at the core of our IT infrastructure, is increasing, we need to find automated ways to detect and predict issues, manage the infrastructure, schedule workloads, etc.
Solution: Increasingly, IT facility managers employ “data collection, aggregation, and analysis for operational management” of complex ecosystem components, as a holistic process, now named Operational Data Analytics (ODA) by Bourassa et al. [2a]. Already, ODA has many important applications, as illustrated in Figure 2.
A Venn Diagram of Operational Techniques for Distributed Ecosystems
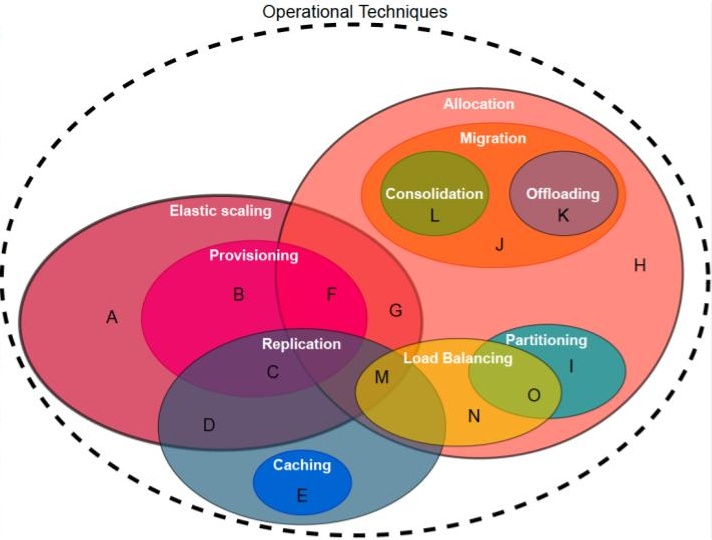
Figure 3. How are the operational techniques used in distributed ecosystems related? (Image source: [3].)
Problem: Many operational techniques can help satisfy various non-functional requirements; for example, in Module 4 we have introduced resource provisioning and allocation to help achieve high performance and scalability. Distributed ecosystems often employ not one but many operational techniques, across and within components. It is important to understand how they relate to improve their collective operation.
Solution: Figure 2, developed by a team led by Stijn Meijerink and Alexandru Iosup at VU Amsterdam, introduces a Venn diagram that relates ten operational techniques [3]: allocation, caching, consolidation, elastic scaling, load balancing, migration, offloading, partitioning, provisioning, replication. (Other operational techniques exist.) Notably, there are large areas of overlap, sometimes between more than two techniques, which suggests design teams must consider carefully when to use such techniques together, and how.
Simulation of Distributed Ecosystem Scenarios, both Short- and Long-Term (Figure 4)
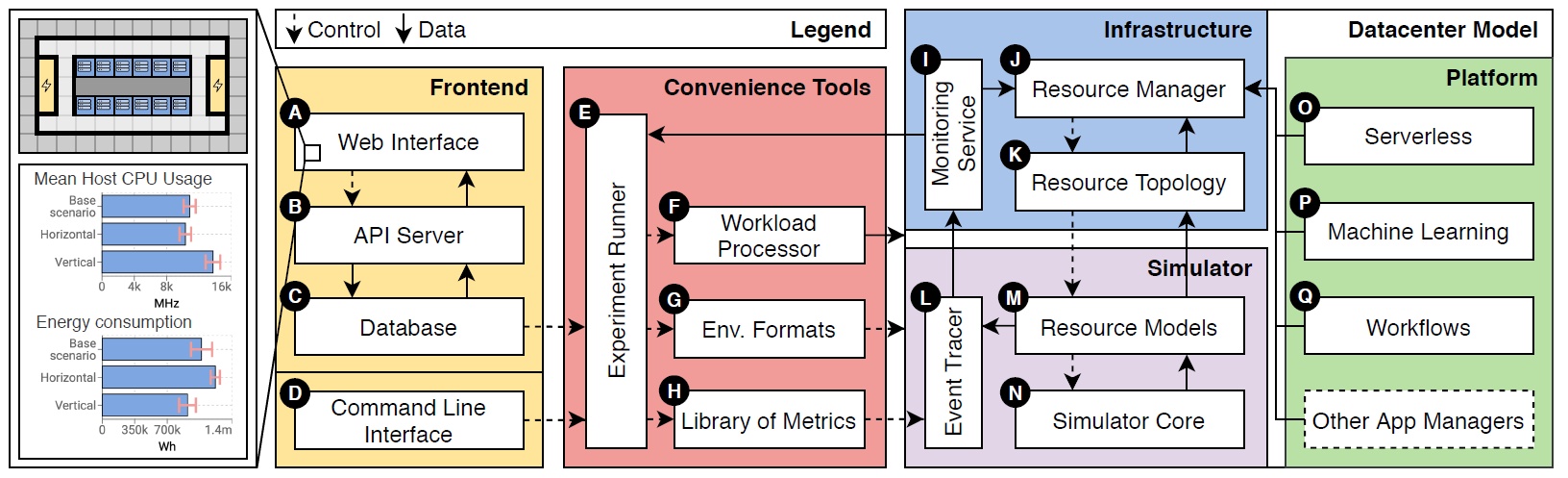
Figure 4. The OpenDC architecture for collaborative simulation of data center ecosystems. (Image source: [4].)
Problem: As IT infrastructure relies increasingly on complex distributed ecosystems that exhibit various forms of dynamic behavior, understanding their operation before putting them in production becomes essential. Real-world experimentation at full system scale, which can be beneficial for a variety of scenarios and problems, is not feasible for such infrastructure; analytical models also suffer from scalability and often still need to be refined.
Solution: Simulation is a critical part of exploring data center technologies, enabling scalable experimentation with millions of jobs and hundreds of thousands of machines, and what-if analysis in minutes to hours [4]. OpenDC is a simulation tool that provides such features, supporting short- and long-term scenarios, risk analysis, automated capacity planning, etc. The core of OpenDC is developed at Vrije Universiteit Amsterdam and TU Delft, in the Netherlands.
As the field matures, important new tools will emerge. Still, their distinguishing feature will remain an ability to address the challenges of this class of systems of systems, where properties turn into super-properties.
References:
[1] Nikolas Herbst, André Bauer, Samuel Kounev, Giorgos Oikonomou, Erwin Van Eyk, George Kousiouris, Athanasia Evangelinou, Rouven Krebs, Tim Brecht, Cristina L. Abad, Alexandru Iosup (2018) Quantifying Cloud Performance and Dependability: Taxonomy, Metric Design, and Emerging Challenges. ACM Trans. Model. Perform. Evaluation Comput. Syst. 3(4).
[2a] Norman Bourassa, Walker Johnson, Jeff Broughton, Deirdre McShane Carter, et al. (2019) Operational Data Analytics: Optimizing the National Energy Research Scientific Computing Center Cooling Systems. ICPP 2019 Workshops.
[2b] Alessio Netti, Micha Müller, Carla Guillén, Michael Ott, Daniele Tafani, Gence Ozer, Martin Schulz (2020) DCDB Wintermute: Enabling Online and Holistic Operational Data Analytics on HPC Systems. HPDC 2020.
[3] Stijn Meijerink, Erwin van Eyk, Alexandru Iosup (2021) Multivocal Survey of Operational Techniques for Serverless Computing. White Paper. Available upon request.
[4] Fabian Mastenbroek, Georgios Andreadis, Soufiane Jounaid, Wenchen Lai, Jacob Burley, Jaro Bosch, Erwin Van Eyk, Laurens Versluis, Vincent van Beek, Alexandru Iosup (2021) OpenDC 2.0: Convenient Modeling and Simulation of Emerging Technologies in Cloud Datacenters. CCGRID 2021.
Working Approaches to Solve Problems in the Field
Two broad approaches to solving problems in distributed ecosystems already exist: the top-down (holistic) and the bottom-up (incremental) approaches.
The Top-Down Approach attempts to identify or construct a general solution to the problem, from which practical solutions can later emerge. Common generalizations include, in decreasing degree of abstraction, design principles, reference architectures, and design patterns. Design principles cover the most important frameworks or philosophical concepts for the entire work, for example, “use services” [1] or “resource management and scheduling is a first-class component” (this course). Reference architectures cover, with various degrees of detail, how all implemented systems should behave; their lower-detail versions are very useful to engage diverse stakeholders, whereas in-house engineers can use their high-detail versions to implement a working system. For example, the two-tier architecture typical of early data-driven applications turned around the year 2000 into a three-tier architecture, separating business logic from operational concerns and leading to serverless computing in the late 2010s. Design patterns capture how experts, especially in practice, address the main concerns for specific problems. For example, the design pattern of placing a load-balancer before replicated business-oriented servers is commonly used in practice to increase scalability.
Examples: The top-down approach was used at Amazon when designing their new distributed computing platform at the end of the 1990s [1], which is now industry-leading and the basis of the lucrative Amazon Web Services cloud platform. Almost simultaneously, it was used to blueprint grid computing by a global community led by Ian Foster [2].
Advantages: The top-down approach promises holistic solutions to key problems and the ability to solve diverse problems with one solution. For the higher-level abstractions, that is, principles and low-detail reference architectures, if the experts involved represent a large organization or community, and there is follow-through on what they agree, this can lead to a large impact on the class of problems that are being solved; many would start solving them in the same way, a uniformity that leads to exploring many possible solutions while learning from best-practices.
Disadvantages: The top-down approach starts naturally from the highest-level concerns and related abstractions. Even with excellent designers involved in the process, the road to productization is long, and the message can get lost. A low-detail reference architecture can be difficult to implement to achieve its theoretical or design goals. Worse, it may not even capture the right problems or make the right decisions.
Another disadvantage of the top-down approach is that, by its holistic nature, it affects every process and requires every stakeholder to buy in. In particular, system engineers will convert high-level abstractions into working (eco)systems, so they must agree to the principles, reference architectures, and design patterns.
The Bottom-Up Approach focuses on starting with a working solution to a partial problem, from which it can iteratively construct increasingly larger solutions to increasingly more complete problems. Common solutions to partial problems include, in decreasing scale, decomposing domains to solve individual operational pillars, integrating existing components, and proofs of concept.
Examples: The bottom-up approach has been taken by organizations that identified a niche where they could succeed, then gradually expanded the core product, through internal development or acquisitions.
Advantages: The bottom-up approach is likely to deliver lower time-to-market than the top-down approach, because it focuses on concrete and timely problems. This approach also allows for identifying practical problems relatively early in the process.
Disadvantages: Increasing the scale and complexity of problems, even by an order of magnitude, can expose limitations with the current approach that may not be easy to address or even break the current approach. Ideally, such situations are identified early, but solving for the new scale or complexity often leads to experts switching to a top-down approach.
References:
[1] Werner Vogels, Distributed Computing Manifesto, Amazon internal document 1998, published as tech blog in Nov 2022.
[2] Ian T. Foster, Carl Kesselman (2004) The Grid 2 – Blueprint for a New Computing Infrastructure, Second Edition. The Morgan Kaufmann Series in Computer Architecture and Design, Morgan Kaufmann.

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/