



4.2.3 Scheduling in Distributed Systems
Course subject(s)
4: Resource Management and Scheduling
We have seen in Section 4.1.1, Introduction Module 4, that schedulers in distributed systems cater to sophisticated users with specialized workload needs. Often, the same distributed system has to cater to many users and thus to many needs. For their operational scale, many distributed systems (and, further, ecosystems) also support the objectives of multiple stakeholders, including data center operators and consortia sharing infrastructure, who have their own, possibly competitive goals. As we will see in this part of Module 4, the user and operator goals may also conflict. All these make distributed scheduling far more complex and diverse than scheduling in smaller, single-computer systems.
Scheduling in Distributed Systems is a Contract Client-Operator
In a distributed system, it is common for both the clients (or resource consumers, or users) and the operators (resource providers) to share responsibility for resource management and scheduling (RM&S). Thus, the main goal of RM&S in distributed systems is to:
| Main goal: Establish and enforce a mutual agreement between resource consumers and providers about what resources are provided, why, and how. |
Let’s understand better how the agreement is established and enforced in practice, by considering what happens in a mid-scale data center. Figure 1 illustrates the example.
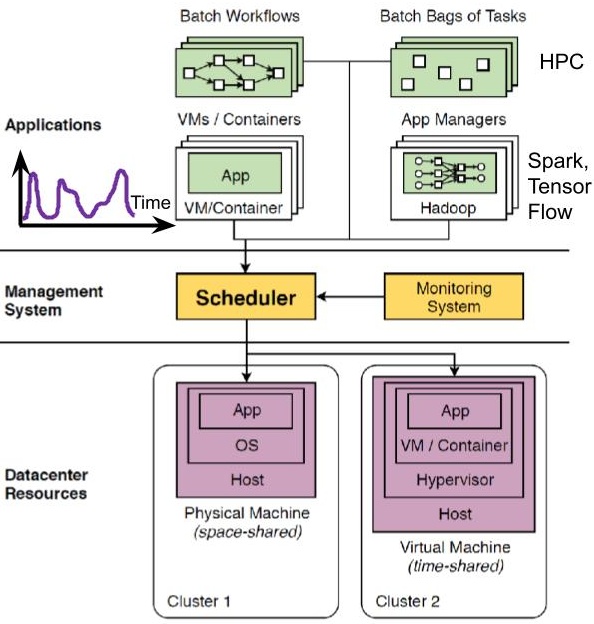
Figure 1. A common architecture for scheduling in mid-scale data centers. (Source: Georgios Andreadis, Fabian Mastenbroek, Vincent van Beek, Alexandru Iosup (2022) Capelin: Data-Driven Compute Capacity Procurement for Cloud Datacenters Using Portfolios of Scenarios. IEEE Trans. Parallel Distributed Syst. 33(1).)
Clients use various programming models to submit jobs – structured or unstructured collections of tasks -, creating workload for the system. Jobs can be diverse, for example, the figure illustrates batch bags of task and workflow structures, short-lived container-based apps and long-running VM-based services, and managed data and processing jobs such as Hadoop and Spark.
The more advanced clients often have an important say in the selection, aggregation and disaggregation, provisioning and allocation, and other advanced operational techniques that manage resources. Overall, clients aim to maximize the value derived from using resources, or to minimize the response time. Many other objectives are possible.
Operators use various system architectures to create their infrastructure and provide an execution environment, typically for many clients. Workloads arriving from many clients can exhibit strong dynamics, both short- and long-term. Resources can be very diverse and heterogeneous, physical and virtual, with diverse capabilities, performance, etc. Operators use scheduling and many other resource management techniques to execute user workloads, trying to maximize resource utilization or the revenue they obtain (simplified, income minus penalties) by running jobs for clients. Operators can pursue many other objectives.
In Figure 1, the operator has built a largely automated RM&S system, which at runtime is supervised by a team of data center engineers. Jobs run through the management system, centered around the scheduler, which makes and then takes decisions about which set of resources to use for a specific part of the workload. To make informed decisions, the scheduler relies on data collected by the monitoring system. The scheduler and the monitoring system are much more complex than depicted here, operating hierarchically and often distributed. The team of engineers runs the data center through a constant stream of high-level decision-making, high-level tuning of the scheduler and other parts of the RM&S system, and detailed tuning of the current conditions, but even after all this activity a vast majority of the decisions are taken by the scheduler. Increasingly, to avoid ‘flying blind’, the scheduler is also required to explain its decisions to engineers.
Challenges of Scheduling in Distributed Systems
Many challenges appear when scheduling in distributed systems:
Responsibility for decisions. Operators and clients can each take important decisions about workload and resources. For example, operators must decide which resources to give to which job (and thus client) and for how long. Clients can also be faced with decisions: Which resources to lease? When? How many? When to stop? From which operator? And what is the utility, that is, how much value would these resources provide toward running the client’s workload, relatively to how much they cost?
Scale, which we consider in a quantitative but also qualitative sense. Distributed systems often have to scale to millions to hundreds of millions of concurrently active tasks. Time-wise, operational concerns and decisions can span nearly 15 orders of magnitude (from microseconds to days, then from days to years). Space-wise, the number of resources and services that have to be managed at runtime for large-scale applications can span 6 orders of magnitude (from a handful to millions of processing cores). Qualitatively, the nature of the tasks and resources can also present different granularities and thus different problems of scale; the current trend of disaggregation and reaggregation of resources and services across operational and geographical boundaries is likely to increase with new generations of ever-faster networks.
Conflicting objectives. Often, the client and operator objectives are conflicting. For example, improving response time for clients typically involves reducing system utilization. This exemplary tension is addressed in traditional scheduling approaches, so many results that appear there – virtualization to increase system sharing and provide isolation, right-sizing the system, scheduling for both classes of objectives – can also be leveraged for distributed systems, albeit, with adaptations and extensions.

Figure 2. Diversity of objectives when scheduling in distributed systems. (Source: [1].)
Diversity of objectives. Scheduling objectives can cover a wide range of issues, as surveyed recently by Versluis and Iosup [1] and illustrated by Figure 2. These can include optimizing or satisficing for combinations of:
- The makespan (or runtime) of jobs, where the makespan is the total time elapsed between the start and finish of the entire job.
- Meeting job deadlines.
- Cost, typically either total per workload or budgeted period, or spent per job.
- Energy consumption, an optimization goal driven by the increasing use of electricity by IT infrastructure and increasing cost, both financial and environmental, of producing electricity. Energy-efficiency objectives are also becoming popular.
- Resource utilization, which denotes the efficient use of allocated resources. Resource utilization levels of 70% are possible in domains such as supercomputing, and many grid computing facilities reported even higher values, yet the utilization of clouds catering to enterprises, and especially to small and medium businesses, can be as low as 6%–12%.
- Some schedulers attempt to load-balance, i.e., distribute the work over workers so that they are roughly equally loaded.
- Fairness is often a target of scheduling for multiple users, with many possible definitions.
- Enforcing priorities, often expressed per client or group of clients.
- Risk, a large and increasing objective for many IT infrastructures. Risk arises from resource contention between jobs, but also from many other operational hazards. Responding to these hazards while meeting the quality of service requirements set by users reduces risk.
- Security and privacy, which are very broad objectives (and specialized forms of risk).
- Fault tolerance, which is (simplified) the system’s ability to respond to faults such that jobs do not stop producing correct results.
- Data locality, which prevents data from being shipped unnecessarily between system components.
- Fidelity, which expresses the quality of the output. For example, a video-streaming operation can produce output at various levels of quality, with higher levels typically requiring much more compute and networking resources.
- Job throughput, which expresses the amount of output produced per time unit, and response time. Focus on throughput is one of the theoretical differences between distributed and parallel systems. When the output is not expressed in terms of completed jobs, but of data, these two objectives are better expressed as bandwidth and latency, respectively.
Other objectives may exist, and new objectives may emerge or become prominent.
Diversity of scheduling decisions. Modern schedulers in distributed systems can take a variety of decisions, about provisioning resources for a group of jobs or client, about allocating specific resources to a job or task, about partitioning data and computational work, about offloading data and computational work to a specific set of resources, about disaggregating and reaggregating resources, etc.
Reference:
[1] Laurens Versluis and Alexandru Iosup (2021) A survey of domains in workflow scheduling in computing infrastructures: Community and keyword analysis, emerging trends, and taxonomies. Future Gener. Comput. Syst. 123: 156-177. DOI: https://doi.org/10.1016/j.future.2021.04.009

Modern Distributed Systems by TU Delft OpenCourseWare is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Based on a work at https://online-learning.tudelft.nl/courses/modern-distributed-systems/